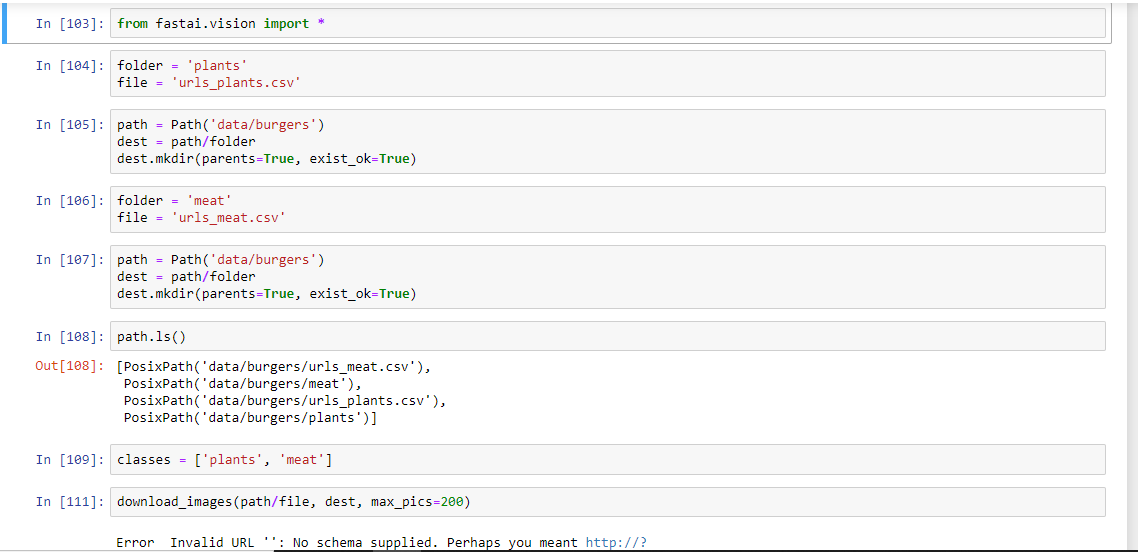
I am trying to get going on part 1, creating my own image data set but am running into some issues. This is my code, with the error I am receiving at the bottom ( and the error is repeated multiple times going further down the notebook).
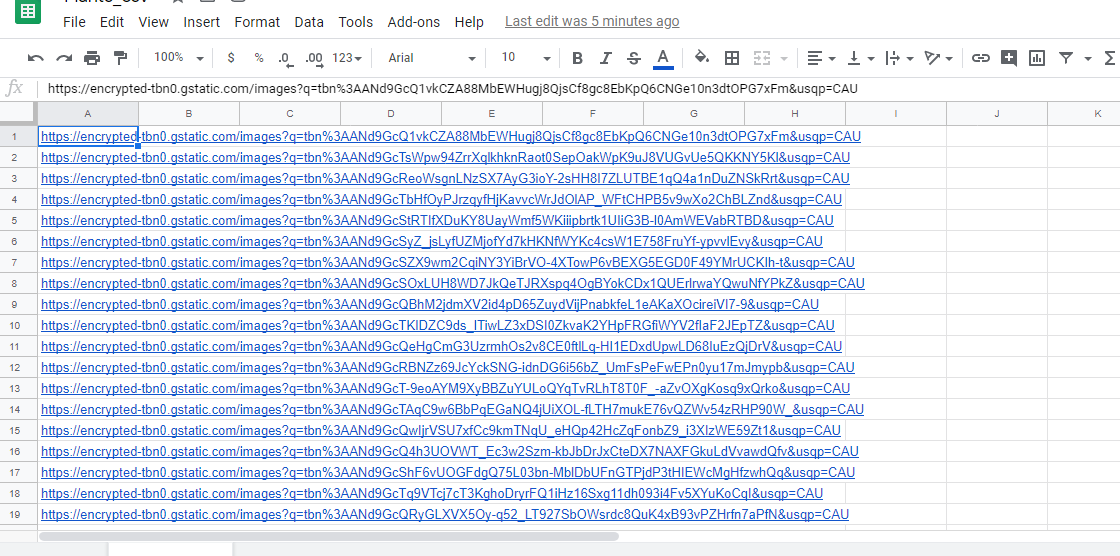
I checked my csv file and it appears to have a url on everyline. When I copy and past the url it takes me to the image that it should. So I’m still not sure what the problem is. This is what my csv file looks like.
Thank you for all your help but I am still very confused. The discussion you sent me explains they’re cached images, but not how to get images without the encryption. Every one of the urls that I downloaded have the same exact encryption. The code I used to download them was this: ‘urls=Array.from(document.querySelectorAll(’.rg_i’)).map(el=> el.hasAttribute(‘data-src’)?el.getAttribute(‘data-src’):el.getAttribute(‘data-iurl’));
window.open(‘data:text/csv;charset=utf-8,’ + escape(urls.join(’\n’)));’
Even when I change my search settings to show only images posted in the last 24 hours, all of the urls have the same encryption.
Actually. I think I MIGHT have finally figured out my problem. My max_pics was equal to a number greater then the amount of image urls I had. I changed it to 80 and am not receiving the same error!