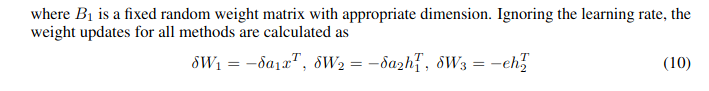I’ve been trying to branch out from learning by courses and trying to read/understand/implement from papers. I liked the idea of learning without backpropagation, found this Direct Feedback Alignment paper, and got stuck on it all of yesterday.
I’ll owe a huge debt to anyone who can clarify.
I made this Colab notebook to better share my question.
Basically, I can’t figure out how the dimensions of the matrices described in the paper could possibly be used in the calculations described in the paper.
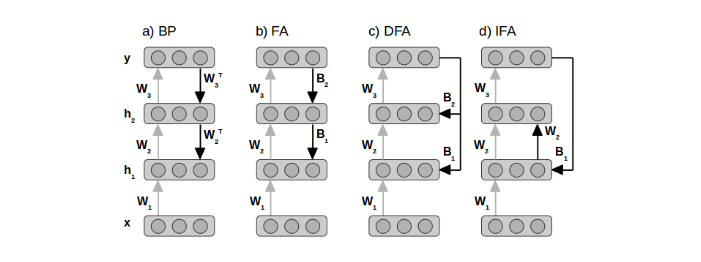
What are the shapes of B2 and B1?
If I follow the equations through, I end up needing to matrix multiply B2 by the Error and then elementwise multiply that by W2.
That ends up being an equation with dimensions ?,? @ 64,1 * 64,64, and I get stuck because I can’t think of a way to matrix multiply anything by 64,1 to get 64,64. I assume there’s an implied transpose? Should I be doing 64,1 @ (64,1).T * 64,64?