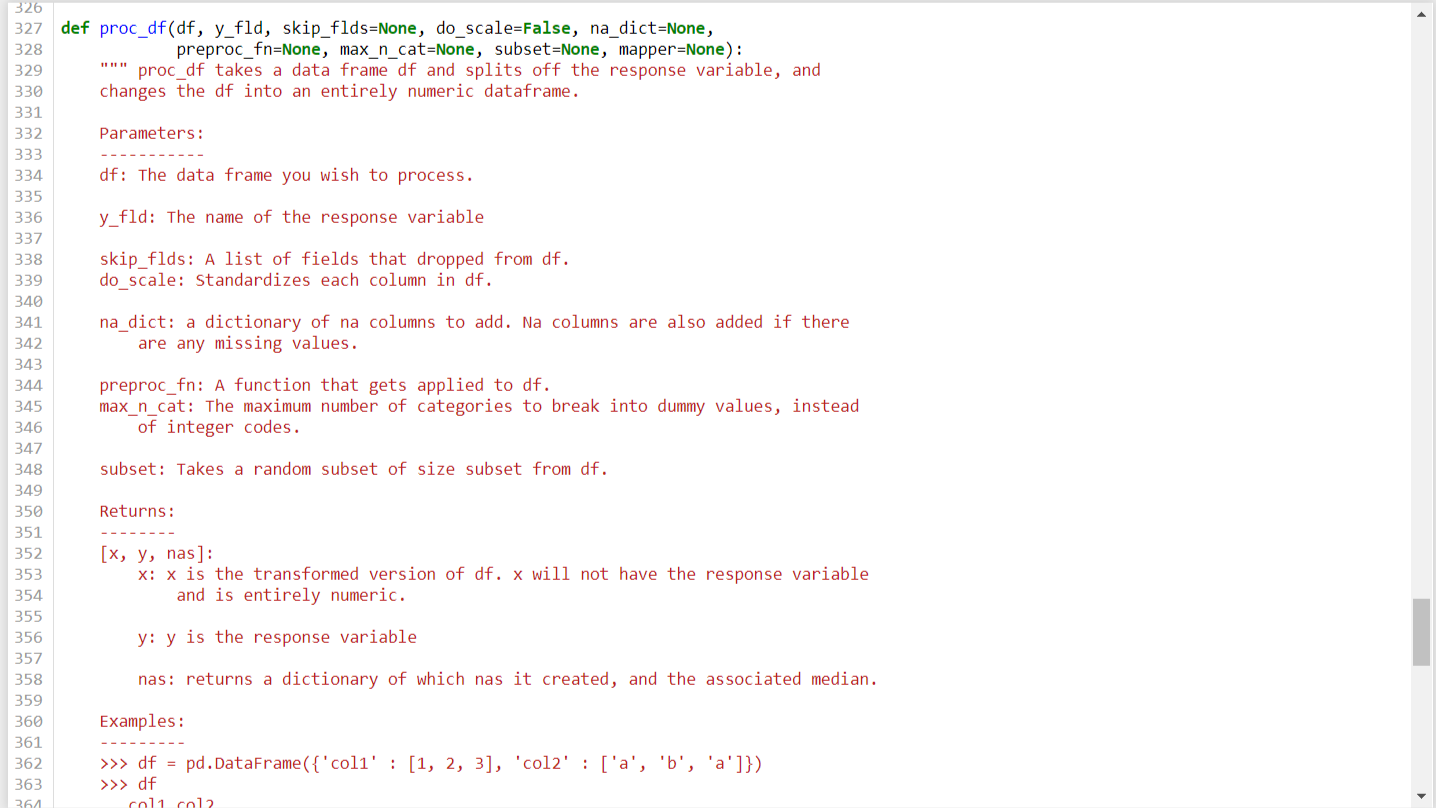
I have a few questions related to the proc_df function in structured.py
The docstring does not contain an explanation of the mapper argument. How is the mapper argument used in this function?
The docstring indicates that three variables are returned, but the Rossman notebook indicates that mapper also needs to be unpacked. If I unpack this function to three variables it returns `ValueError: too many values to unpack (expected 3)’. Does the docstring need to be updated or am I misinterpreting the function?
The mapper variable lets you know the values ( mean and standard deviation ) used for scaling of variables. This happens because in the Rossman example, he used do_scale = True. If you set it to false, it will only return 3 variables. This can be seen in the result ( res variable) in the proc_df function. The mapper variables gets added only when do_scale =True.
res = [pd.get_dummies(df, dummy_na=True), y, na_dict]
if do_scale: res = res + [mapper]
return res
The fastai library is used for machine learning too which normally doesnt need scaling of variables. I think the docstring was made from that perspective. But applying neural nets needs normalization. Yes you are right, it needs to be updated.
Thank you @soorajviraat. Is it correct that the mapper variable is required to make predictions on an unscaled set of data? If so, how is this done? Let me know if there are set of lectures in the ML course that address these questions.
To use other scalers, would we have to basically make another version of proc_df?
If I’ve understood correctly, you wouldn’t want to use the proc_df scaler with a non-normal feature or one with outliers. right/wrong?
Can anyone explain how the techniques in the ML course lesson 2 notebook (Random Forest interpretation) would be affected by the use of a scaler? (I’m assuming it wouldn’t as the tree splits on everything, but if we drop based on unscaled, might we miss things other models can see?)
I came across the sklearn robustscaler, which it would seem to me would be good to use with data of varying distributions and quality. I’m still jumping around (and repeating) the DL and ML lectures, but as far as I can tell, this concept hasn’t come up