For lesson 6 I was trying to make two changes to the code.
-
Input a text beside Nietzsche. Being more hackerish than philosophical I pulled in POC GTFO Issue #1 (apologize for the language) which seems to work great. I did notice that the vocab size was a little longer but figured it would just increase the epoch times.
-
Is where it got weird. I altered the code to have one additional input, but the training seems off. It looks like it is predicting the 4th, not 5th character each time. The output looked like this.

I figured the training set was too small. So I added in the first 10 POC GTFO issues. Now the vocab size has doubled, including some Russian characters.

But the problem continued, and I wondered if I was overtraining the model. So I made a loop that would run an epoch and stop if the loop ever correctly guessed the “k” in book. Book appears several times in the text, and there is also reboot and boon. Perhaps those words are throwing it off.
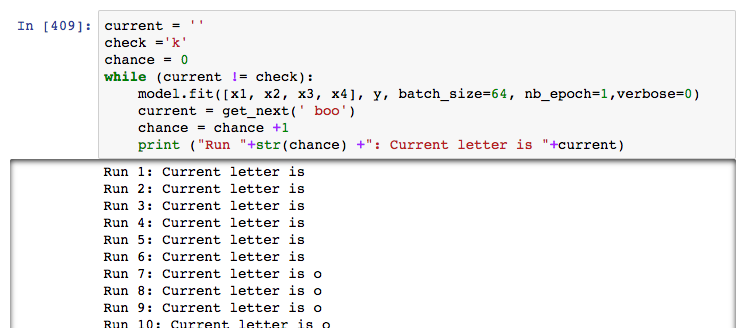
It gets o within 7 runs (loss around 3) and when I run it overnight, it stayed on o for 8 hours. I consider the high possibility that my code is super goofed up or the increased vocab size it to blame. Reluctantly, I change the model back to the original 3 letter in and 1 out to predict the 4th letter.
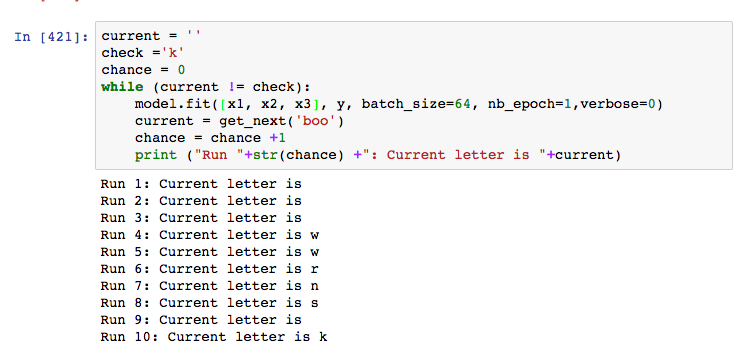
Instant success! This result makes more sense to me because the changing characters suggest that learning has taken place before the final result. Surprisingly, on average loss is also around 3 when k appears. Similar to what I see up in the 5 letter prediction. In other tests, it also guesses words like boot and boon. Now I know the text has been added correctly and the increased vocab size is not the problem.
I am somewhat confident that the error for the 5 letter predictions is still selecting the 4th and while I still have no idea why that happens it is time to move on. I wanted to share my enjoyment of the trouble shooting. Here is my code if anyone is interested.