@jonmunm
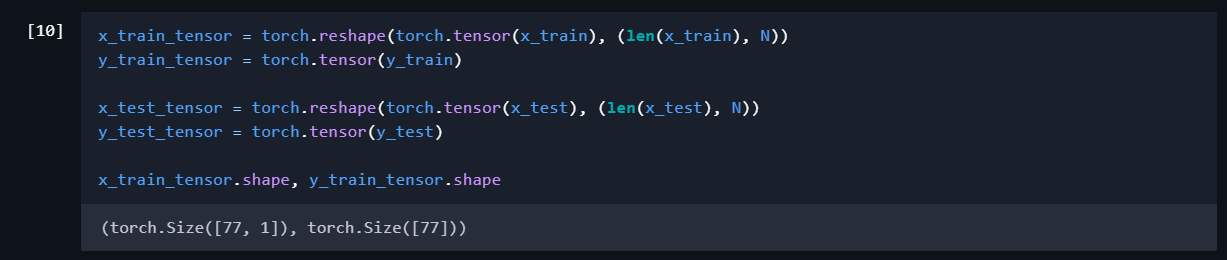
Yes. I think I see the problem. Your model output is of the shape torch.Size([77, 1]), but the targets are of size torch.Size([77]). The loss function “broadcasts” these two tensors. Basically, whenever you do an operation on two (or more) tensors/vectors/matrices, which are not of the same shape, they first need to be made of the same shape. This process is called broadcasting.
Here’s how broadcasting works: Python(more specifically numpy/PyTorch) starts from the right most dimension, and then goes left. if one of the dimensions is 1 or does not exist, then the 1 would be changed(broadcasted) to the value of the other dimension value (or if the dimension does not exist, then a new dimension is created with that value).
Here, tensors are, say, A and B, of shape [77] and [77,1] respectively, and they need to be broadcasted. So python looks at the rightmost values which is 77 for A and 1 for B.
So Python Broadcasts the tensor A over the rightmost dimension of B, making B of the shape [77,77].
Next, the other dimension is checked. which is 77 for B and non-existent for A. So, a new dimension is created in the leftmost position in A and then the leftmost dimension of B is broadcasted over the new dimension, making A of the shape [77,77].
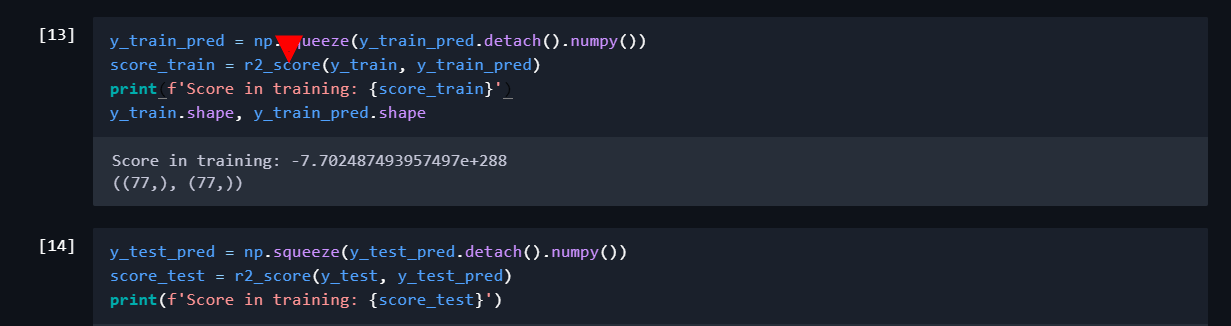
You see, the loss function wouldn’t make any sense because of the shape of the broadcasted tensors.
You should reshape the output tensor as [77,1] too, (and [20,1] for the validation set).
Then the loss function wouldn’t have to broadcast, because both the target and the prediction would be of the size [77,1]. That should do the job.
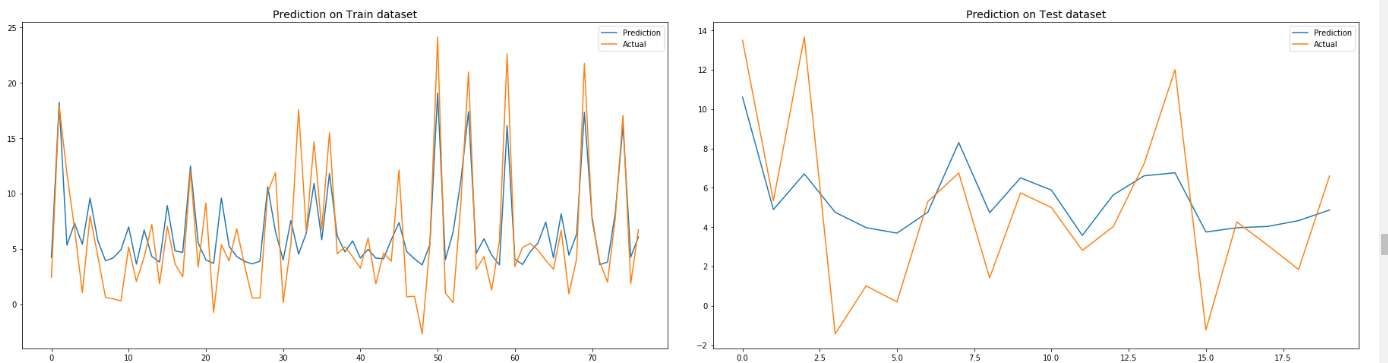
If not, then we’d further debug for any other issues!
Cheers, stay safe
If you’re confused with how broadcasting works,or simply want to learn more, check out the numpy documentation for broadcasting




 … Here en Chile is 15.00 hrs …
… Here en Chile is 15.00 hrs …