Hi,
this discussion actually comes from this thread but I thought it might be relevant here. Maybe someone can explain if/why it is necessary to store the paths in lists, is that a design decision or just “chance”?
Key issue are memory problems when dealing with large datasets (i.e. kaggle quickdraw), in this context the following (copied from other thread):
So, now some further research into our memory problem:
The key thing I cannot wrap my head around is this:
- I am able to run training with num_workers=4 (set on the DataLoader, not the DataBunch) on 10.000 examples. I run that for 3 epochs without problem.
- if I now change the examples to 30.000 and only 1 epoch it crashes.
- the crash happens WAY before the number of iterations is reached that are neccessary to process ONE epoch of 10k examples using otherwise identical settings. Therefore the training itself cannot really be the cause.
- the only difference in the dataloader I can think of is the length of the itemlists and labelists. So how could that lead to such a massive problem? (I mean those are huge and have to be copied into all workers. So this could potentially deplete RAM. Why they are so huge is something to be looked into as well.)
Looking into this deeper led to the realization, that just by loading the little over 10 million files into an itemlist, the python process consumes over 3 GB of RAM. I had to read a lot about memory management but what is clear is that pytorch uses fork() to create the worker processes. That means a worker is basically created as a copy of the main process with everything in it. In theory as long as nothing is changed that should mean they share the memory, but in practice as either subprocess or main process change stuff, the memory actually gets copied/duplicated for each process. So if we have a giant main process, that will not be good for forking workers from it!
So, looking into this deeper, the reason why the process is so bloated, is because all the paths to the files in fastai Itemlists get stored in lists of Path objects. That seems to be a very memory inefficient way of storing things. The question is, why we store the filepaths as lists at all. pathlibs Path.iterdir() offers a generator that has basically zero memory footprint, I am not sure why fastai converts everything into real lists.
So that leads to this situation (10200000 file paths in a list of Path objects):
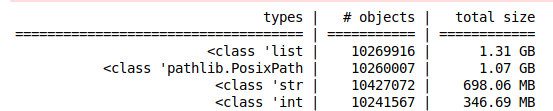
more than 3 GB of RAM used just for the filepaths!
So, if it is necessary to have lists for some reason and not use generators 2 options at least help the situation:
A) Storing lists of string paths:

-> reducing memory footprint by 2GB (“only” 1.1 GB for storing the filepaths)
B) As normally the path is passed separately, it would be enough to just store the names (or maybe relative dirs). with names only:

reduces memory footprint by another 300 MB.
While having lists in memory worth 800MB is not nice, forking that and creating 8 copies would not overflow my RAM. Copying 5GB processes just 4 times already kills my 16GB system. (5GB because the label list adds another 1.xGB and the learner object adds more.)
Any insights welcome! Thanks.