@rachel: Thanks so much. That makes sense. Sorry this was a silly mistake. I will fix it and hopefully the results will be better. I shall post updates.
1 Like
Thanks @rachel. That was it. It solved my problem.
1 Like
thanks for your answer @brianorwhatever . Turrns out the reason it was not working properly was me not setting shuffle=False when creating batches as @rachel said.
That was it @rachel . With a little bit of finetuning, I could easily get 98% accuracy.
Thanks again!
Hi Jeremy, I am trying to run kaggle statefarm full dataset on the model you used for the sample. It is taking 360 seconds per epoch on p2 instance. Your ipython notebook shows only 114 seconds. What do you think I am doing wrong? I am using the exact same code from ipython notebook (but not the AMI provided with this course, could this be the problem)?
Here is my code (for creating train and val split) and the model I used to train: https://github.com/singlasahil14/kaggle-statefarm
Hi Sarno, I am trying to finetune the vgg model without any data augmentation. The best accuracy I could get to is 68.94%, while in jeremy’s ipython notebook, the accuracy was like 79%. What do you think I am doing wrong?
Here is my code for creating training and validation split, and code for training the model (copied mostly from ipython notebook) https://github.com/singlasahil14/kaggle-statefarm
Reposting from ‘Lesson 3 discussion’ as this seems a more appropriate place.
Hi,
I was thinking about statefarm problem and had some thoughts and questions around it.
a. Statefarm problem seems to have lesser variety in the type of objects that are present in images i.e. each image would have a human and some objects within a car. Given VGG16 has been architectured as well as trained to detect a much wider set of objects, it feels like an overkill to use all convolution layers of VGG16 as is for statefarm problem. Any comments/insights regarding this ?
b. Statefarm image categorization would be determined majorly by the relative position of the objects w.r.t each other i.e. ‘hands-on-steering-wheel’ implies undistracted driver VS ‘hands-on-something-else’ implies distracted driver. How can the fact that ‘actual objects matter less Vs relative position of objects matter more’ be factored in to architect the model ? Any insights/guidelines on this ?
c. Unrelated to statefarm, what are relative tradeoffs of using a larger convolution kernel(55 instead of 33 for e.g.) ?
Thanks,
Ajith
1 Like
I’ve been using a finetuned version of VGG19 for StateFarm as a starting point to build up better models. I ran the test function(same as in vgg16.py) and it seems to be running for quite a while now. I understand that this is 79,000 images and it would take a bit but its’ been on for close to 40 minutes now.
Anyone facing similar issues? Thanks!
Hi there,
so did you managed to get the weights?
are they here http://www.platform.ai/models/
thanks!
Ajith,
I had thought about the same questions, here are my findings:
TLDR; winning solution uses VGG16 and manually crops certain parts of the image for the CNNs to focus on.
- Statefarm dataset is relatively small, and reusing the convolution layers from VGG would ideally help the model avoid overfitting.
Visualizing what VGG+keras is looking for:
excellent visuals (zeiler / fergus style):
- Its quite clear that certain parts of the image are more important than others, and the leading results certainly had many creative methods to think about this.
This discussion showed a competitor’s method to display with a very cool heatmap of what the CNNs were focusing on:
1st place solution uses VGG16 and combines 3 images; a cropped image around the head, a cropped image around where the hand may be, and the original image itself.
10th place solution involved finding the area around the drivers body, and cropping the image to around that.
Statefarm was a super cool competition to work on, and I feel like it was a quantum leap from dogs-and-cats competition in terms of deep learning understanding. Hope my findings were helpful, the fact that the winning solution used something more elegant in the spirit of deep learning was certainly very encouraging!
best,
Jerry
7 Likes
Hi Jerry,
Thanks for this reply. This is very informative.
Regards,
Ajith
Lesson 7 shows how to do this. ![]()
Note also that the winning method uses k nearest neighbors. I haven’t tried it yet but I suspect this is a critical piece of the solution.
My best State Farm Score is 0.715.
Would like to share my model and how I trained it.
Maybe someone will find it useful.
In general I used conv layers of VGG16 trained model as input to a new untrained simple bn/dense/dropout layers.
It was trained in 3 steps and after each steps I submitted my test prediction at Kaggle.
- created an augmented batch and predict it on VGG16 conv layer. output prediction is the training set for my untrained model. (spent A LOT of time realizing the augmented batch must not be generated with shuffle=True or else labels will not be correct)
- predict and trained with a 5x trained data.
- predict test images and used it for pseudo labeling. over fitting wise, this was the best train.
Also two main question/thoughts i have after this training
-
Big difference between my validation loss and the actual computed competition loss.
In my training I reached val loss of 0.3778 - which i can dream about that score on State Farm test set.
I believe my validation set was build OK, and I separated different drivers for training and for validation.
I wonder what is a the way to close this gap between my val loos and the test loos. -
During training i was also over fitting a lot (except when using pseudo labeling).
MY question is, if Over fitting, is it useful to continue training a model that its train accuracy is very high, say 0.99 and up?
Is it possible to improve val loss/acc when model train acc is so high?
Trouble with training final_model (combined bn_model and conv_model) on StateFarm dataset
I am having trouble with the training of the final_model (which combines the Vgg convolution layers (fixed at original weights)) with the new fully connected layers (including Dropout(p=0.6) and Batchnorm layers).
My bn_model trains quickly to a validation accuracy of ~80% (training accuracy of ~99%). However, when I load these bn_model weights into the final_model in order to train it further, the final_model performance worsens during training. In the first epoch training accuracy drops to ~10% with validation accuracy dropping to 53% in first epoch down to ~20% in the fourth epoch (training accuracy continuing to hover around 10%).
These are the steps I followed:
- Created a ‘static’ dataset (using get_batches with shuffle = false)
- Split off the convolution layers from the Vgg16 model and compile with the RMSprop optimizer with lr=.0001. Set the layers to .trainable=False.
- Constructed the bn_model (with the layers as per the Lesson 3 notebook i.e. 3 dense layers, 2 dropout layers, 2 batchnorm layers) and compiled with RMSprop optimizer with lr=.0001.
- Generated the feature inputs (training and validation) for the bn_model with conv_model.predict.
- Trained the bn_model. Within one epoch the training accuracy went to 88.6% with the validation accuracy at 79%.
- Added the bn layers to the conv_model to create the final_model. Loaded the bn_weights for the bn layers of the final_model. Compiled with RMSprop optimizer with lr = .0001.
- Run the final_model with the train_batches and val_batches created during step 1. The model accuracy starts out at that of the bn_model, but then quickly drops off to a training accuracy of ~10% in the first epoch.
I have done the following steps to try to isolate the problem:
- I used .evaluate() on both bn_model and final_model with the data used for training and confirmed that they get the same results. This hopefully rules out any discrepancy between the feature data created with the conv_model for the bn_model and the ‘raw’ image data used for the final_model training.
- I compared the weights of the convolution layers of the final_model and conv_model before and after training to confirm the that weights were originally properly loaded and that the .trainable=False ensured that these layer weights are not adjusted form the original Vgg16 weights.
- I did the same comparison of the fully connected layers of the final_model with the layers of the bn_model to confirm that the weights were the same prior to training the final_model.
- I also did a further round of training on the bn_model to ensure that it did not show the same behaviour as the final_model. With further training the bn_model continued to improve the training accuracy (with the validation accuracy oscillating between ~60% and 80%.
I’m having no luck uploading screenshots from my model, but hopefully the description above is clear enough. I will again try later.
Any ideas of what might be causing this to happen?
Any pointers of further trouble shooting I can do?
Many thanks
Rauten
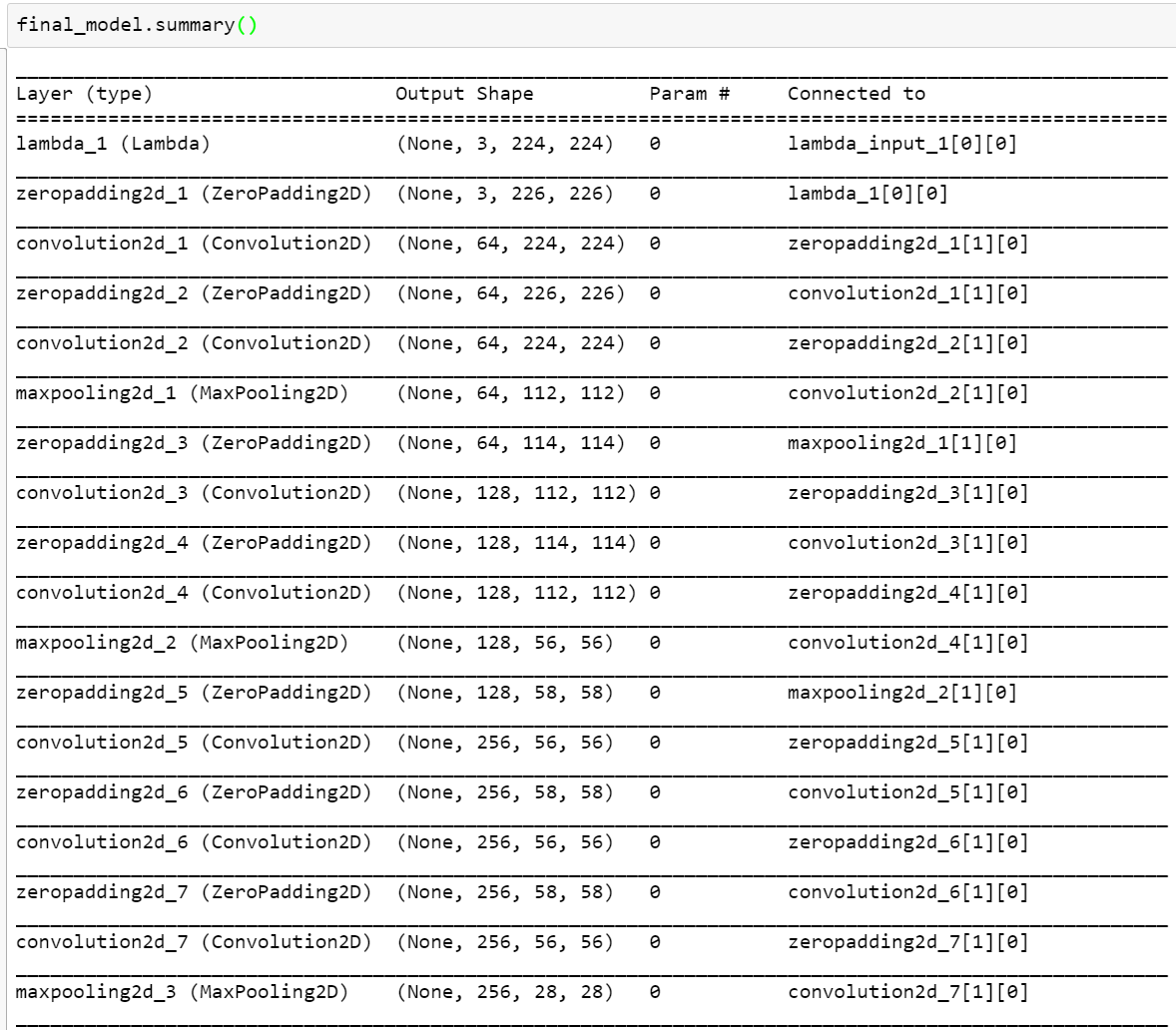
A model.summary() of your model would be helpful as well a Gist link to your code.
Also read about model.built which can be set to True/False - maybe it will help.
Not sure, but make sure that after compiling the combined model the layers that need to be non-trainable are indeed non trainable.
BTW, why in the first place , you are looking to combine the models? predict with conv_model and use it as an input for bn_model…
RE: Trouble with training final_model on StateFarm dataset
@idano
Thanks for your reply.
Herewith the screenshots that I couldn’t get to load yesterday.
- Screen shot of bn_model training
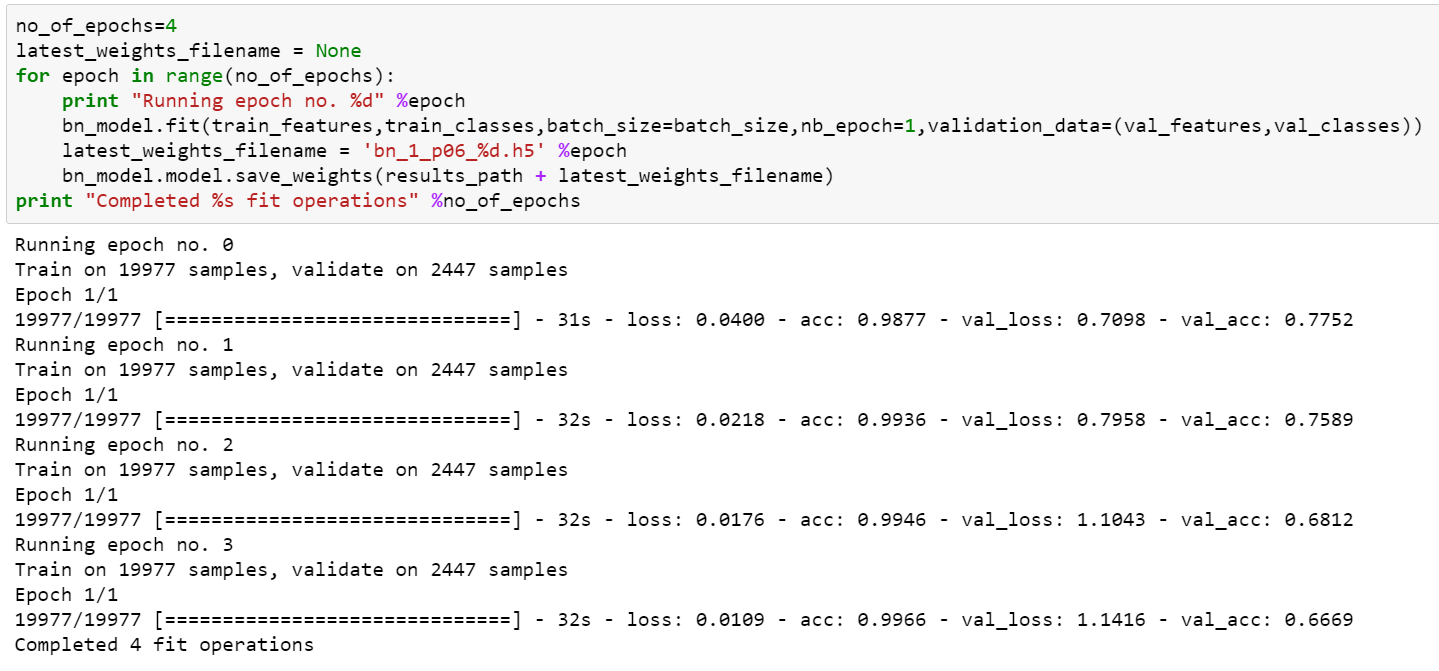
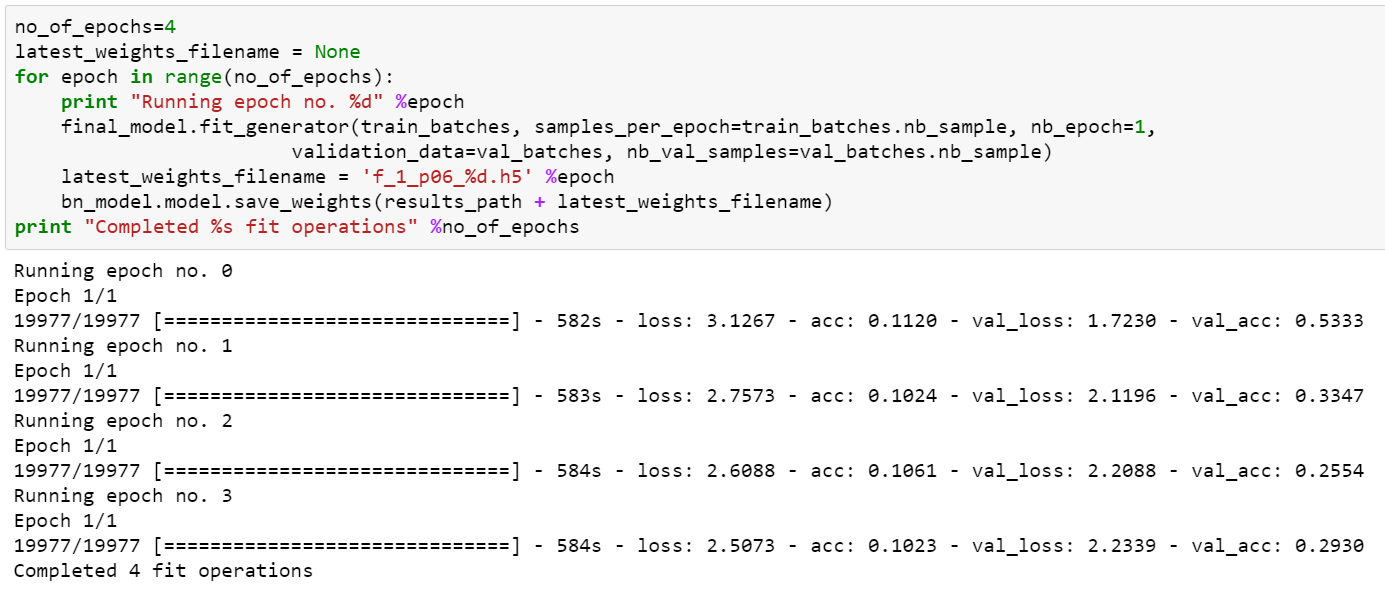
'2. After training the bn_model, I copied the weights of the fc layers of the bn_model to the final_model and then trained the final_model on the same data. Here is a screen shot of the training outputs:
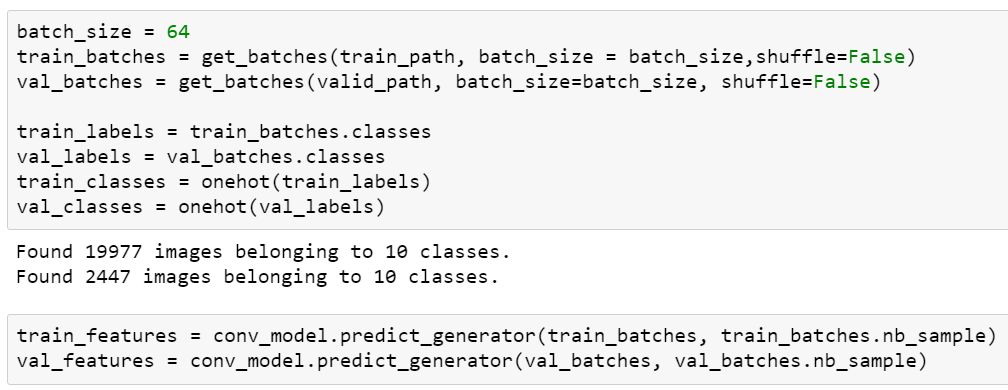
'3. This is how I loaded the batches for training and generated the training data for the bn_model.
I am not familiar with Gist, but attempted to create a Gist with my notebook. Please let me know if this worked:
Thanks
Rauten


@jeremy - I can’t the part of the lecture, notes, or notebook that talk about how to combine batches together. Can you direct them to me? Thanks
There’s a get_data function in utils.py nowadays…
1 Like
hrr… not sure how the get_data function can solve the MemoryError that arises when concatenating augmented data with the original data. After more digging, seems like other people are saving their data with bcolz and then generating through the two batches like this:
X = bcolz.open(path + 'train_convlayer_features.bc', mode='r')
y = bcolz.open(path + 'train_labels.bc', mode='r')
trn_batches = BcolzArrayIterator(X, y, batch_size=X.chunklen * batch_size, shuffle=True)
model.fit_generator(generator=trn_batches, samples_per_epoch=trn_batches.N, nb_epoch=1)
3 Likes