The quality of generative image algorithms is compelling. I’m wondering if we can combine StackGAN, Neural Doodle, pix2pix, and space-time video completion to create a synthetic video clip. A “real” movie. Thoughts?
Just for giggles, here’s a potential path forward:
1. Long term vision
Given a paragraph of text, the algorithm will generate a photorealistic video sequence with audio included. The algorithm obeys the details and movements requested by user
2. Medium term
Given a sequence of video frames, the algorithm will generate an output sequence that matches the video details/movement logically
3. Short term
Given a sequence of semantic segmentations or neural doodles, the model will output the logical next segmentations/blobs in the sequence. For example, if there’s a cartoon blob going down for 10 frames, it’s likely to be drawn even lower for the 1st generated frame (i.e. 11th frame).
Modify StackGAN to take a semantic mask/neural doodle as input and train it to generate a new image in the location specified by the user
Extend StackGAN to generate the same image over and over given the same inputs (e.g. text, neural doodle, id, segmentation map)
4. Very short term
Record a down-sampled game of Pong and build a model that predicts where the ball will be next given a sequence of previous frames (bounding boxes or segmentations)
Modify generative GANs to output semantic segmentation maps similar to an input segmentation map (or text query: “I want a segmentation map with a cat and a person in front of a building”)
5. Next Steps
Investigate the state-of-the art in a few of these topic areas and determine a good first prototype
Consider text-to-video directly. You could scrape clips and hand label them, like people did for image caption datasets. For example, “a bird flying”, “a cat walking”, or “a person jumping” for 50 to 75 frames. If that’s too far past the state-of-the-art you could try text-to-doodle-video or text-to-simple-drawing-video and then apply neural doodle or pix2pix on each frame and add temporal coherence. The organizing idea would be to get just enough data to decide whether to get more data. If you get a good preliminary result you could then scale the labeling process.
You could also check out video-to-text papers to look for datasets and ideas for reversing the direction.
Video extension
You may find Comma.ai’s driving simulator paper interesting.
“We show that our approach can keep predicting realistic looking video for several frames despite the transition model being optimized without a cost function in the pixel space.”
Although I think that a “next generation photoshop” would be both more useful to more people (and therefore more lucrative ), and also quite a bit easier (and less resource hungry). The papers you kindly linked to are just the kinds of things that would be relevant to this too.
Further, such an approach could naturally be extended to video later I suspect.
(If you’re more interested in video than still photos, then of course you should follow your interest - I’m sure either way your idea could have a lot of life. And I hope to work on the still image approach sometime soonish regardless, so we may be able to share some ideas between projects.)
I imagine Adobe/Google are already working on this? Google just released a few DL features in its Snapseed App. I’m fascinated by this idea too, though. If we were to build a super-simple 1 feature prototype, which feature would you suggest we tackle first?
I think this is interesting (humans are really good at finding flaws in images, but cartoons could be more forgiving and also less computationally demanding). Maybe a good first step is to apply the CycleGAN/StackGAN to a training set of cartoon images?
More Papers
Video Pixel Networks (Fall 2016)
I think Jeremy presented on this, but it’s currently state of the art on MNIST moving digits dataset.
Generating Videos with Scene Dynamics (Fall 2016)
These MIT students released their code, models, and dataset (1 years worth of video) online free. They generated some pretty interesting footage, albeit small in size.
It seems like we can combine these to build something interesting. Text --> Sketch --> Animation --> Video?
Relevant Datasets
Charades
Charades is dataset composed of 9848 videos of daily indoors activities collected through Amazon Mechanical Turk. 267 different users were presented with a sentence, that includes objects and actions from a fixed vocabulary, and they recorded a video acting out the sentence (like in a game of Charades). The dataset contains 66,500 temporal annotations for 157 action classes, 41,104 labels for 46 object classes, and 27,847 textual descriptions of the videos.
Action Recognition http://crcv.ucf.edu/data/UCF101.php
UCF101 is an action recognition data set of realistic action videos, collected from YouTube, having 101 action categories. This data set is an extension of UCF50 data set which has 50 action categories.
Personally, I think one big missing thing is fixing up old scanned photos or old digital pics shot on less good cameras. It seems like a good match for DL too since older scans / pics will often be less high res, so can be handled more quickly, and are good targets for adding/improving color (often old pics are washed out), super-resolution, removal of noise, etc.
I think a really polished super-res app would be a fantastic start, personally. Creating a real-world web app would be an interesting engineering challenge, although using Google Cloud ML would be a possible short-cut (at least at first).
But really I think this is a highly personal choice - what would you like to exist? What would you like to show off to your friends - and what do you think they would be most excited to use? What would make your friends and family happy?..
Denoising is a good use case. As an example for dance photography, one has to use high shutter speeds, which limits the amount of light that can get into the sensor. Even if we use a large aperture, good images are hard to get. One solution is to raise the ISO, but this introduces ISO noise. If we can remove ISO noise cleanly then even a poor camera can compete with a high end camera with good sensors that supports high ISOs. I am pretty sure there is a good demand for an app like this. Combine this with super resolution and you have a winner. Generating training data for denoising is also relatively easy.
Just read Learning What and Where To Draw
The demonstrate conditional GANs that accept the location of where you want the GAN to generate the image. They have a nice GitHub too
One can generate objects in a specific region by conditioning on the last heatmap of a semantic segmentation network
Synthesize a Music Video by sampling images conditioned on lyrics
Music video idea is interesting. Could even just be a video/image search engine and auto generate a slideshow based on text (a fiction book, business document, movie script, etc.)
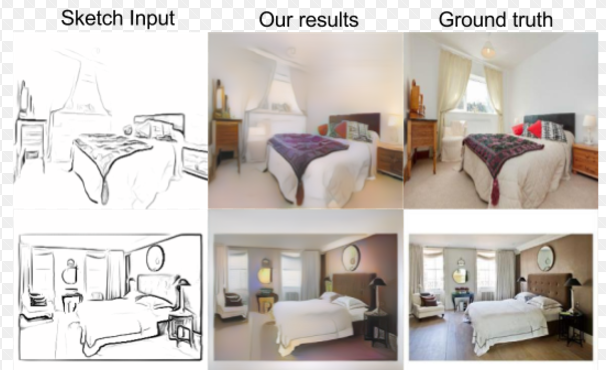
@thunderingtyphoons@jeremy I’ve been playing around with photorealism style transfer and I think that can add to the denoising idea you mentioned above. See images below.
I have been wondering if you could take slightly out of focus photos and turn then into sharper images. I know from recently looking at old family photos that plenty of them suffer from being taken on cameras with bad quality focus and are only just out of focus. It seems that this should be reasonably easy to make datasets by adding some blur etc.
This (and denoising + SR) could also be really interesting to apply to audio to get clearer audio for phones and hearing aids etc.
Wow @xinxin.li.seattle tell us more about what you did here! This looks fascinating. Especially the bottom pair - you’ve taken a washed-out image and made it much richer.
Apologies for my sloppiness, the washed-out image was actually the output of photorealistic style transfer. It would have been nice if it were the other way around
@brendan@Matthew This is all super interesting and something I’ve been thinking a lot about as well. If you guys ever wanted to hack on something along these lines, I’d love to join.
That sounds great. I’ve been playing around with applying vanilla WGAN to generating anime sketches. Not working so far, but maybe this new paper from the author of WGAN may help.

 | Two Minute Papers #133")



 ), and also quite a bit easier (and less resource hungry). The papers you kindly linked to are just the kinds of things that would be relevant to this too.
), and also quite a bit easier (and less resource hungry). The papers you kindly linked to are just the kinds of things that would be relevant to this too.