Overview
Does the stable-diffusion model have the “optimal” “shape”?
The stable-diffusion model has 3 main parts (excluding the tokenizer and scheduler)
- Text encoder (e.g. fixed, pretrained CLIP ViT-L/14) - maps input text to embeddings
- VAE (e.g. sd-vae-ft-ema) - compresses / decompresses pixels to / from latents
- UNet - denoises latents
If we can only have so many parameters in a model due to resource constraints, how should we allocate them among these 3 components?
Data
Using our example pipeline from the notebook I noted these parameter counts for the components:
| Component | # of Parameters | Data Size | Percent of Total |
|---|---|---|---|
| Text encoder | 123,060,480 | 492 MB | 12% |
| VAE | 83,653,863 | 335 MB | 8% |
| UNet | 859,520,964 | 3.44 GB | 80% |
| Total | 1,066,235,307 | 4.27 GB | 100% |
So from a model size perspective the UNet is the biggest part by a large margin.
Analysis
One of the interesting findings from the Imagen paper was that “increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model”.
Imagen uses T5-XXL as its text encoder over CLIP or BERT. Parameter counts for the T5 family are:
- Tiny 16M
- Mini 31M
- Small 60M
- Base 220M
- Large 738M
- XL 3B
- XXL 11B
And their figure shows there is much more impact per parameter on the text encoder side e.g. compare the T5 Small to T5 Large jump to the 300 M to 1 B param UNet change.
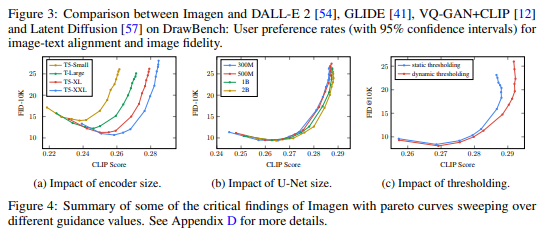
So this raises the question: If we have a fixed parameter budget of 1B params / 4 GB due to memory / resource constraints could we get better images by making the UNet smaller and scaling up the text encoder?
Thoughts for Discussion
As I understand it the choice of text encoder for the stable diffusion model was based on what was readily available (e.g. there were already models for CLIP embeddings) and not necessarily optimized. Should an “optimal” image generation model have a different balance of params between the components? Would it be possible to “transfer learn” the stable diffusion model onto an equivalent with a bigger text encoder?
If anyone has played with different mixes of component sizes I’d be interested on hearing what you found.