Hello all,
Dropout works by randomly excluding some neurons during the training of a neural net, leading to a more robust network with better generalization.
Well, couldn’t we try something similar but instead of dropping neurons, we’d be zeroing out some of the weights and so basically dropping the connection between some of the neurons?
Something like this:
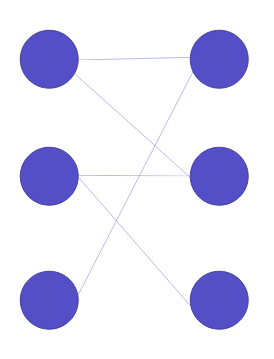
In other words, a random set of elements of the weight matrix would be initially set to zero (unlike dropout though, only before the first epoch. The rest of the training & validation would remain the same).
From there, we’d have two options:
- Train the network as usual, effectively allowing it to change the weights initially set to zero if there is performance to be gained from doing so.
- Don’t update such weights (by zeroing out their gradient as well), deeming them non-trainable parameters.
Tabular datasets are where I believe this method would excel at for a number of reasons:
- When dealing with structured datasets, it is often the interaction between only a few of the features that matters. In that regards, this method could be very helpful in that it would aid the neural net in exploring the relation between the dependent variable and only a subset of the features.
- There might be different ways to get to the dependent variable, with each one giving a slightly different answer (high variance). For instance, maybe the interaction between features 1 and 2 is very predictive of the y-value and so is the interaction between features 3, 4, and 5. Setting the weights to zero initially would enable the model to make different (accurate) predictions using various features, essentially behaving like an ensemble model (I believe this is what dropout tries to achieve as well).
- Weights that are zero are most probably going to remain close to zero (especially if there’s L1 or L2 regularization), resulting in a less complex model.
Like any other algorithm, there are obviously drawbacks as well:
- If it’s a very complex dataset, the model might not be able to realize its full potential (the other end of the first benefit)
- Proper weight initialization and setting a big chunk of the weights to the same value will mess up the mean, STD, etc.
- Probably lot more I haven’t thought of yet.
I tried implementing this in Colab (there’s a lot of cleaning and refactoring needed) and it actually worked surprisingly well: On the blue book for bulldozers dataset, I was able to achieve and RMSE of less than 0.220, better than what I could get with an ensemble of an RF, Extra Trees, XGBoost, and fastai’s tabular model. I’ll try this on other datasets as well and hopefully I’ll see the same improvement!
P.S: I’d very much appreciate it if some of the more knowledgeable users would share any of their ideas, thoughts, or opinions about my code or the technique I proposed.
Sincerely,
Borna