Hello,
I am trying to create a language model in Portuguese from scratch based on the notebook in this link:
https://github.com/fastai/course-nlp/blob/master/nn-vietnamese.ipynb
If I follow the complete tutorial without changing anything it works well. However, since there is no parameter passed to the tokenizer in the TextList.from_folder, I would imagine that the default tokenizer “en” is used, which would be weird. Is this assumption correct?
data = (TextList.from_folder(dest)
.split_by_rand_pct(0.1, seed=42)
.label_for_lm()
.databunch(bs=bs, num_workers=6))
which gets me this data.batch:
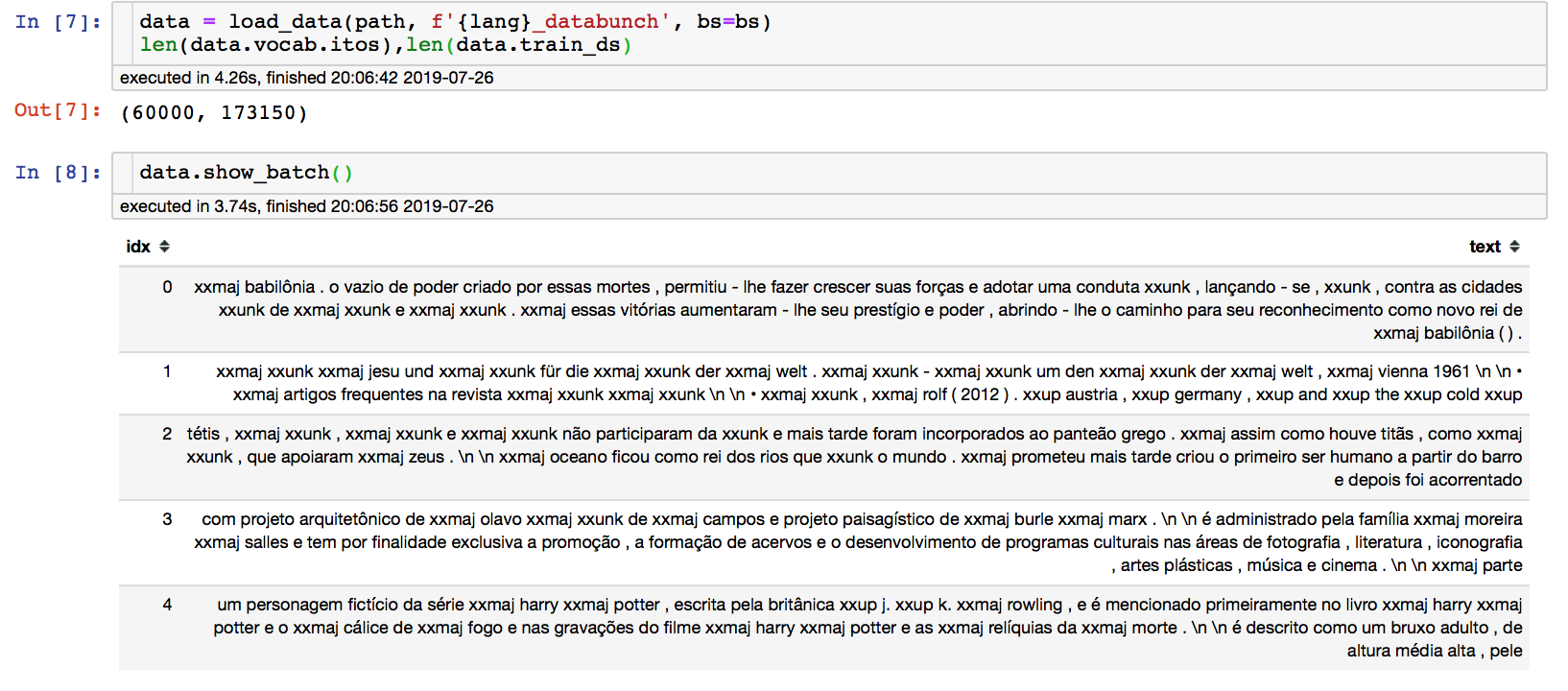
I then tried to pass the correct tokenizer using the processor attribute:
data = (TextList.from_folder(dest,processor=[TokenizeProcessor(tokenizer=tokenizer),NumericalizeProcessor(vocab=60000)])
.split_by_rand_pct(0.1, seed=42)
.label_for_lm()
.databunch(bs=bs, num_workers=6))
But when I check my data.batch I get this:
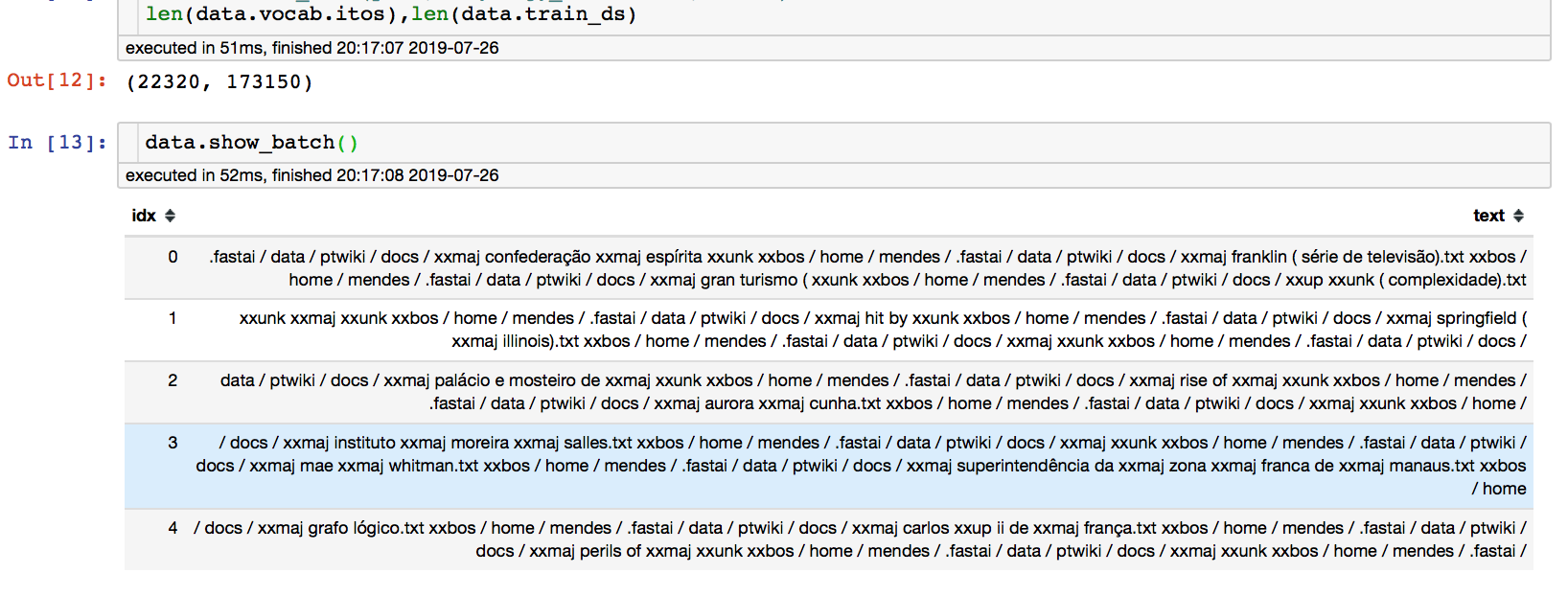
Which means that the script is reading the text paths but not the text content
This error seems to be similar to what happened in this thread
TextLMDataBunch.from_folder seems to be broken #1578
I tried to debug the problem myself, but I could not solve it. Can anyone help?
Thanks