Hi. I found on kaggle a dataset of different fruits and want to build a classifier using it. Unlike lecture 2 dog breeds example, the labels are not in a csv file. The images of different fruits are in different folders, similar to cats vs dogs, but multiple not binary.
Here is code snippets and result screenshots.
os.listdir(f'{PATH}valid')[:3]
['Apple Red 3', 'Physalis', 'Strawberry Wedge']
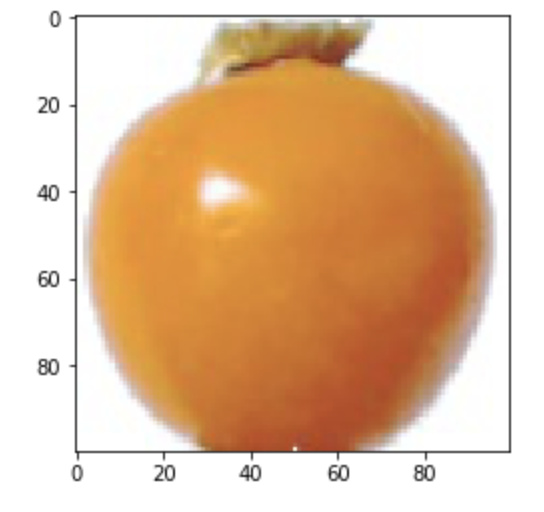
img = plt.imread(f'{PATH}valid/Physalis/{files[0]}')
plt.imshow(img);
arch=resnet34
data = ImageClassifierData.from_paths(PATH, tfms=tfms_from_model(arch, sz))
learn = ConvLearner.pretrained(arch, data, precompute=True)
learn.fit(0.01, 2)
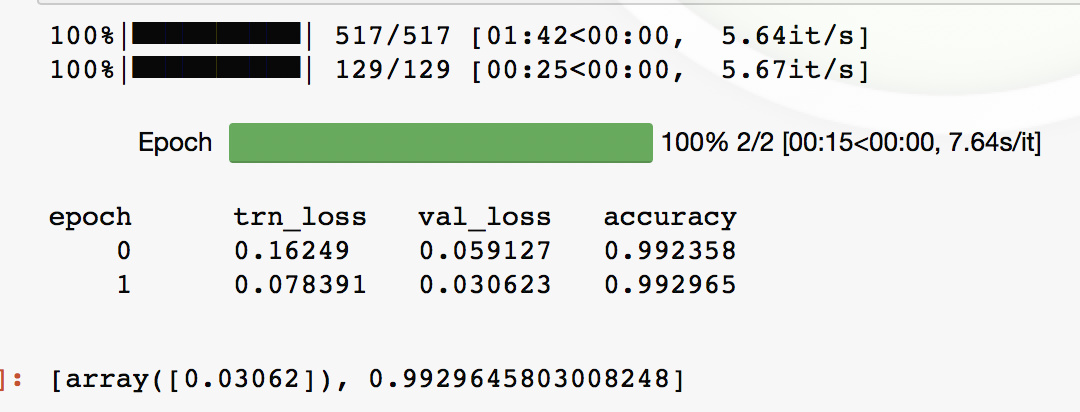
The above results look great to me. Validation loss is lower than training loss and the accuracy is high.
data.val_y
array([ 0, 0, 0, …, 80, 80, 80])
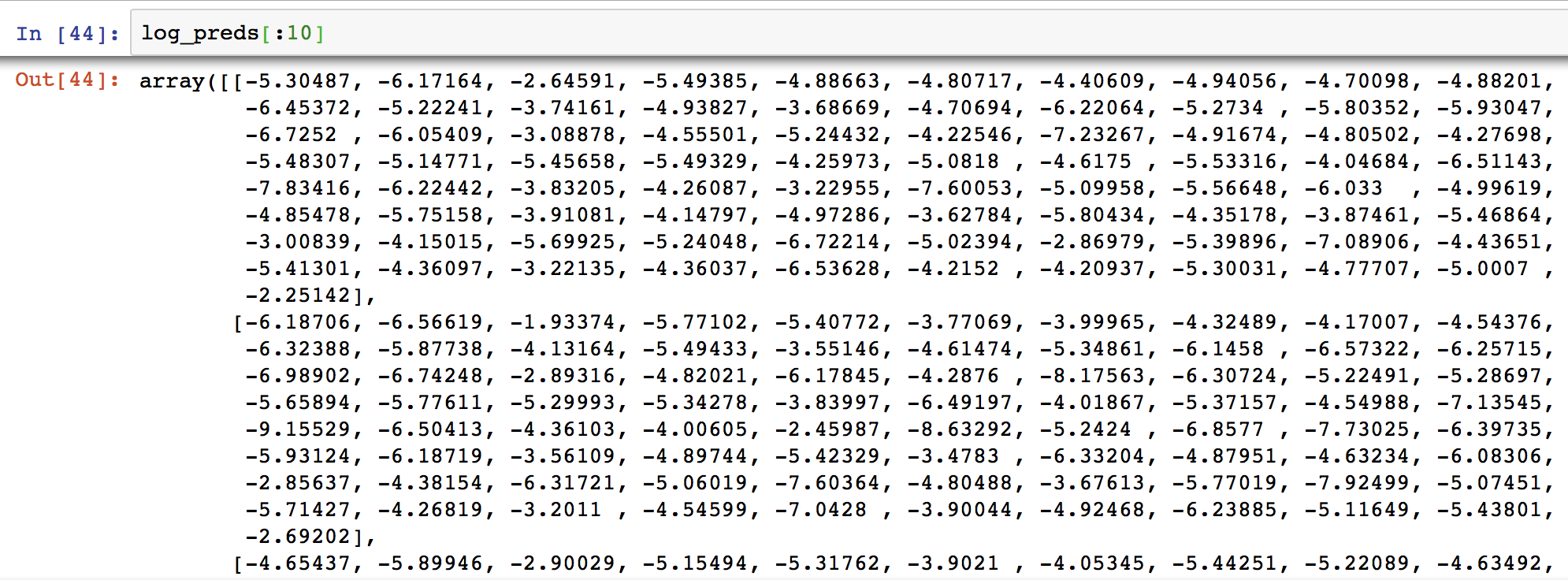
log_preds = learn.predict()
log_preds.shape
(13877, 81)
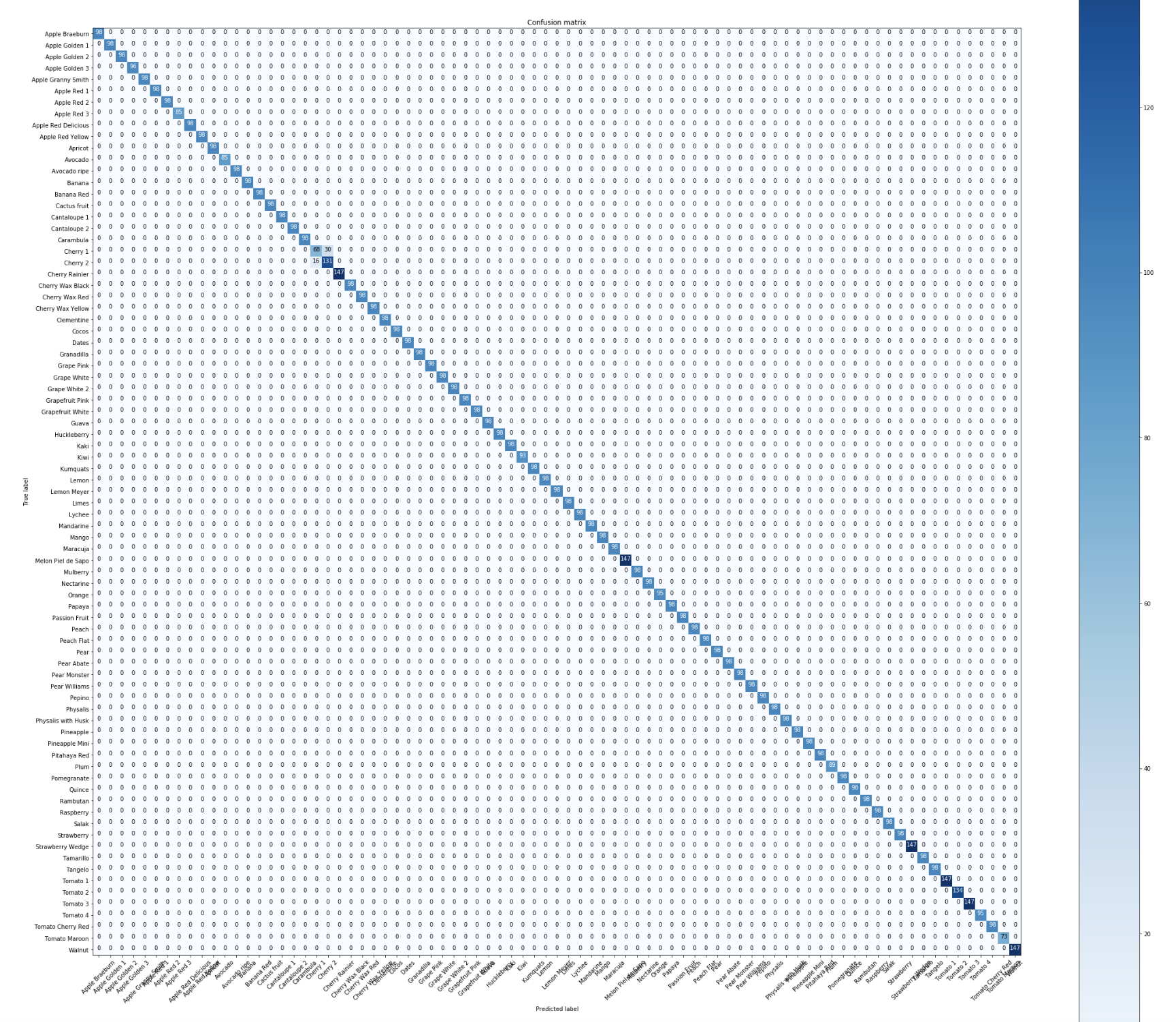
However, when I check the probabilities, I cannot find a single -0.0… They all are much smaller. Hence, it seems the model fails to classify the validation data correctly. Then, why the loss reported earlier was so low.
I am confused. Please advise  .
.
Thanks

 . Will try test data tomorrow and see how the model does.
. Will try test data tomorrow and see how the model does.