Hey, so I played a little with your Notebook and this is what I found out.
So you have two folders: train and test. And you also have a csv file called ‘train.csv’ that is supposed to give labels to the images.
The ‘train.csv’ file provided only provides information (labels) about the images in the train folder.
Check the number of images returned:
and the size of the DataFrame:
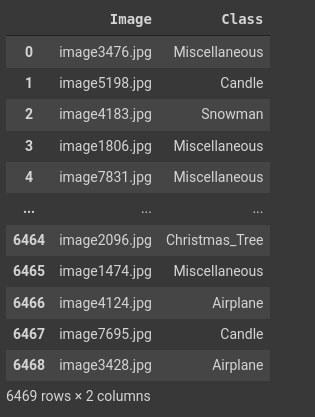
So you need to use RandomSplitter here and not GrandParentSplitter. This will split the images in the train folder to 80% training and 20% validation. The reason we do not include the images in the test set for validation is because we wouldn’t have labels for them.

After training your model, to test it against the test images, you will have to utilize the test_dl method provided by fastai. You can learn about it here:
However since you do not have the labels, you will not be able to check the accuracy of your model against the test dataset.
If you got the Data from a Kaggle competition, one is usually required to submit the result of predictions against the test dataset and they give you a ranking.
Hope this helps!