My dataset folder structure is like these:
- Train
- Valid
- Test
I am creating a DataBlock from scratch, how do i create a custom splittter to use the validation data from the folder instead of the default 20%?
My dataset folder structure is like these:
I am creating a DataBlock from scratch, how do i create a custom splittter to use the validation data from the folder instead of the default 20%?
You should look at all the splitters available: https://docs.fast.ai/data.transforms#Split
One of them fits your situation
thanks 
GrandParentSplitter is exactly what I was looking for.
Hello, I need help with exactly the same question.
How did you use the GrandparentSplitter()?
My path consists of an Image dataset (train and test). So I used
splitter=GrandparentSplitter(train_name=‘train’, valid_name=‘test’)
or
splitter=GrandparentSplitter(train_name=‘path/train’, valid_name=‘path/test’)
I get an error when I use both. I’d be obliged if you could help.
splitter=GrandParentSplitter(train_name=‘train’, valid_name=‘test’)
should work if you have those directories. Since you will pass in path when creating the dataloaders (I am assuming you are using the DataBlock API), this is not necessary
You could link your NoteBook too and I’ll see if I help
No Problem.
So, I can’t run the NoteBook because you are accessing data from your Google Drive.
However, I have some ideas that may help.
So GrandParentSplitter expects a path with the folders you specified when creating it.
You can check out GrandParentSplitter from fastai here
Therefore,
The last part needs to be:
dls = dblock.dataloaders(path)
But this won’t work in your case because you are creating Data from your DataFrame. So you will need to use a custom splitter in this case. The splitter should locate the image, check its parent folder name, and if it is equal to ‘train’ place it in the training dataset, and if it is equal to ‘test’, place it in the validation dataset. Something like Func Splitter from fastai should help us.
Is there somewhere I can get the dataset you are using (maybe from Kaggle or some Github Repo) so I can try and create a custom splitter for this case?
Hey, so I played a little with your Notebook and this is what I found out.
So you have two folders: train and test. And you also have a csv file called ‘train.csv’ that is supposed to give labels to the images.
The ‘train.csv’ file provided only provides information (labels) about the images in the train folder.
Check the number of images returned:
and the size of the DataFrame:
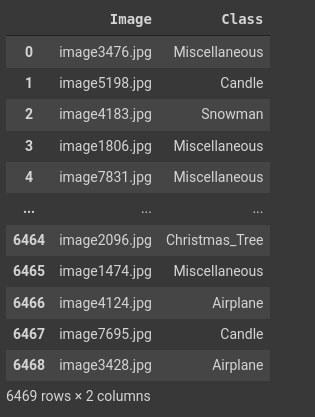
So you need to use RandomSplitter here and not GrandParentSplitter. This will split the images in the train folder to 80% training and 20% validation. The reason we do not include the images in the test set for validation is because we wouldn’t have labels for them.
After training your model, to test it against the test images, you will have to utilize the test_dl method provided by fastai. You can learn about it here:
However since you do not have the labels, you will not be able to check the accuracy of your model against the test dataset.
If you got the Data from a Kaggle competition, one is usually required to submit the result of predictions against the test dataset and they give you a ranking.
Hope this helps!
@jimmiemunyi this helps a lot! I understood what you’re saying and I could solve my problem. Thank you very much!
could you please help me figuring this out?
Hello! Is there any reason why working with random splitter gives better accuracy than with grandparent splitter?
My data is already splitted in train, val and test (70, 20 and 10%)
Thank you!


