I’ve been working my way through an interesting paper that creates a “A Dual-Stage Attention-Based Recurrent Neural Network”
The first stage is meant to select some input series among many to focus attention on. So think of it a lot like feature selection.
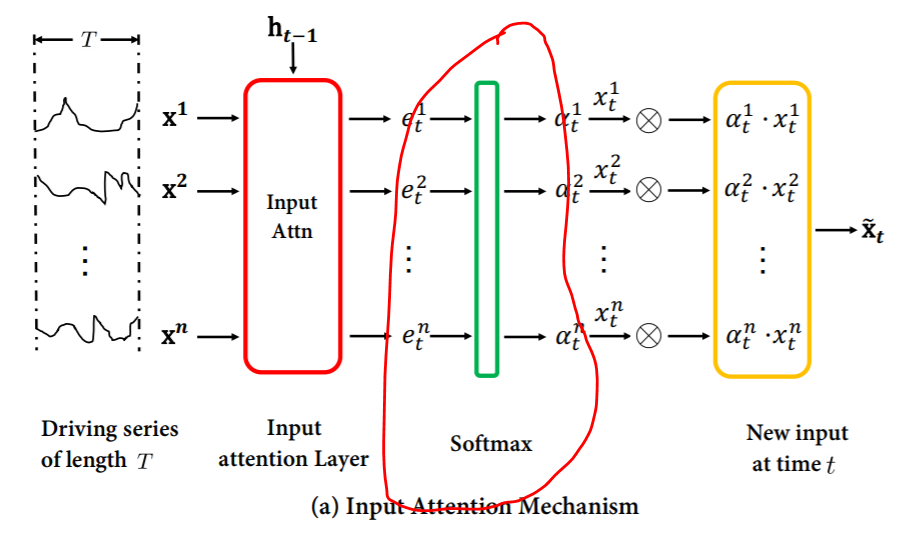
This is where my question starts. I noticed that the authors used softmax to calculate weights that sum to 1. However, this didn’t make any sense to me because after watching Jeremy’s videos i can’t help but anthropomorphize my functions and I know that softmax really just wants to pick one thing. Which means the authors are using a function that tried to pick only one input feature series as important no matter how many or how important the other series are. So i wanted to replace the softmax in this with something else that would allow for multiple feature series to be important and compare the results, the question was what. I started thinking of it as a sort of multi-label classification problem which means sigmoid could be a good function to use. The problem is, i need the output of this replacement function to sum to 1 because they are being used as weights. So I loaded the entropy_example.xlsx spreadsheet jeremy used to teach us softmax, sigmoid and cross entropy and simply added a column that took the sigmoid and divided it by the sum of all the sigmoids. Re-generating the data multiple times in the spreadsheet makes it seem like this is giving me the behaviour i was hoping for.
My question is, does this already have a name? If not, is this a dumb thing to do for a reason i’m not thinking of? My whole goal is just to replace a function that only wants to pick one thing to assign attention weights with a function that can pick many things and assign attention weights to all of them.
Spreadsheet i used is here:
https://drive.google.com/open?id=1qKVkDoMERmgVdf-reKtHQwPzpwiMKiwQ
