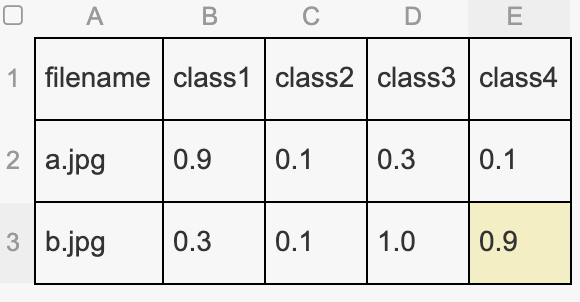
Is there a way to feed in soft labels for multi-label problems? Normally, what we would do is have delimited labels in csv file and then ImageItemList will take care of everything. But that is assuming that every label will be converted to 1. This is what traditional training looks like. But imagine the case where the training labels are not gold-standard and thus the values associated with the labels are probability values (soft labels). My goal is to have soft labels (like 0.8, 0.5, depending on how unsure the ground truth label is) for multiple labels and train the network with those multiple soft labels. The intuition is to backpropagate lesser for those labels with smaller probability values (and thus making only smaller adjustments to weights for those labels where the ground truth is not very sure of the actual class).
Example with plant dataset:
https://docs.fast.ai/tutorial.data.html#A-multilabel-problem
Here the labels such as, partly_cloudy, primary for a particular image will finally be converted to numerical values such as [0 1 0 0 0 1] (assuming that the places of 1’s correspond to the class partly_cloudy and primary respectively and there are a total of 6 labels). But, for example, if we are not sure about partly_cloudy and we are only 70% confident, the soft label scheme would be something like [0 0.7 0 0 0 1] for training label.