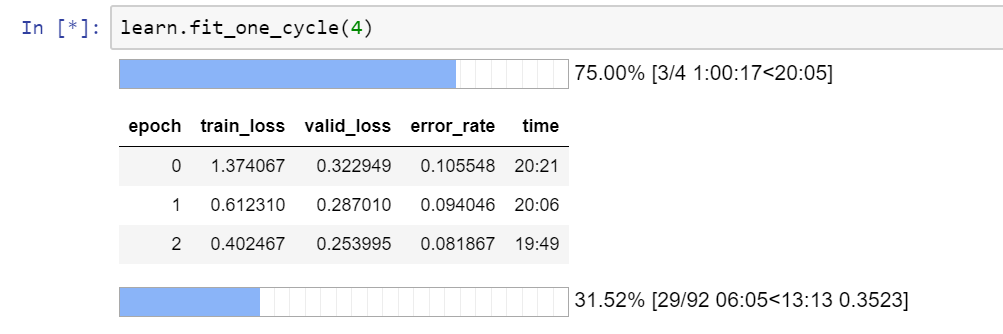
Hello guys, the platform I am using is AWS p2.xlarge with Ubuntu 16.0 Deep Learning AMI. It is fine with all the lines before the training step, but when I run the line:
learn.fit_one_cycle(4)
It took me 15 min just to finish the first epoch. (so about 1 hour to finish the whole training process).
Is this normal for the computational power I have for a p2.xlarge? Do I need to upgrade?
Follow-up: definitely a GPU issue, in my case (running on Google Compute) NVIDIA drivers weren’t functioning correctly. Solved the issue by creating a new VM from scratch, which solved many issues for reasons that are still unclear to me (install was identical to previous one).
Hi! Yes (also see my previous follow up message). I was able to resolve it with a fresh install of the VM. The iterations were slow because the GPU wasn’t being used. Unfortunately I wasn’t able to find the root cause of this issue, but the fresh install resolved it. Worth a shot!