I am using kaggle notebook with a GPU.
It takes forever to train the model described in chapter 10 of the book.
The study of one epoch takes more than 50 minutes.
This is very frustrating and does not encourage experimentation with model training.
Do we really need large models and datasets to learn DL?
Deep learning typically takes a lot of data for training. Just to see the dynamics of things, you may reduce the dataset to a reasonable size and spend less time, however you will not be able to see same quality results as with the full dataset. However, on Colab Pro I spent 28 minutes for an epoch.
Vincenzo, thanks for the reply. Yes, I understand that with smaller models and datasets, we will get a worse result. But is it really that important to us?
Jeremy says in his videos that it’s best to start with a small dataset and a simple model. In the beginning, a high iteration rate between experiments is more important than quality.
On the other hand, Jeremy emphasizes the importance of pretrained models as they allow faster results.
I want to say that the speed of learning is an extremely important factor. Especially if we are not working on real projects, but only studying.
Higher model learning rate → more opportunity for experiments → higher speed at which you learn DL.
Yes, we can say that the problem is in the hardware. But 28 minutes per epoch is still a long time.
In addition, what about those who, for various reasons, cannot afford expensive hardware or a subscription to services?
If you want to prioritize speed, you can just reduce the dataset. The no-brain way would be to delete files from the training set just after having downloaded/untarred them. However, learning is not only learning to do one step after the other, but also to evaluate results, change hyperparameters, look at what gives better results, etc.
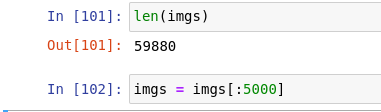
@relu, I will usually reduce the dataset to prioritize speed when I start building a model. Most of the time at this stage, I need to debug the code :D. You can see what I’m doing for my current notebook as below
Iteration speed is vital.
But I believe at some point, dealing with the frustration that the model takes forever to learn is inevitable. You have tech debt, you took code from someone else, you are in rush, … So we need to build the habit of not staring at the screen and doing something else. for example:
Open another notebook-copied and try something else, improve your code, … (if it is on the same machine so be careful not use all GPU or RAM of the 1st notebook)
Open a physical notebook and plan what you will do in the next iteration
I highly recommend live coding sessions of Jeremy in this regard. First you will see his process while a model is running. Second he setup a paperspace it won’t vanish like kaggle or colab. Thirds there is a way to speedup training by using accumulation (if I am not mistaken). He also explain that some models (even small) are pretty good. Forth , I usually have other project(s) to do or learning other stuff while a model is training (even 5 minute per epocs) .
Chapter 10 of the book , congrats.