Hi, I’ve downloaded a dataset of about 13 million reviews from BoardGameGeek and tried collab learning on it. Having lots of fun with it and plan to make a blog out of it.
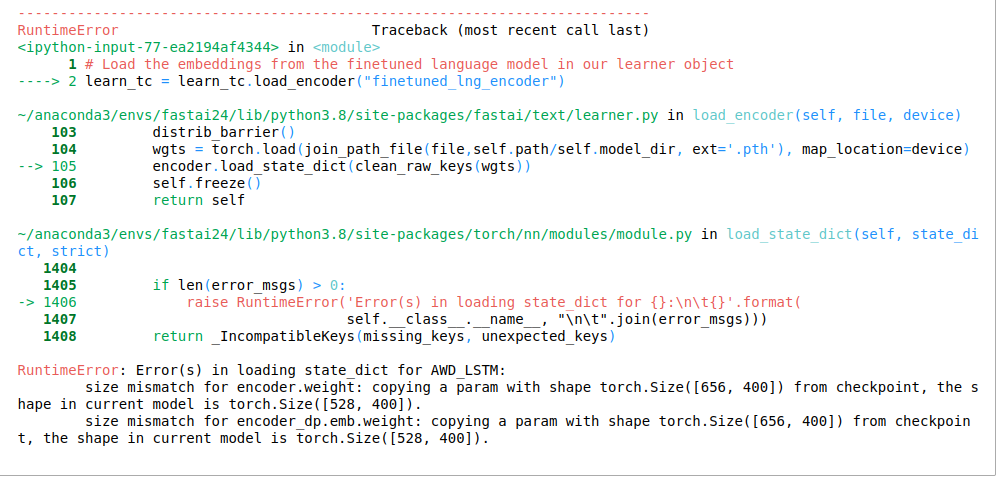
However when I want to load a saved model in a new session, I get an error.
size mismatch for u_weight.weight: copying a param with shape torch.Size([277772, 50]) from checkpoint, the shape in current model is torch.Size([277751, 50]).
size mismatch for u_bias.weight: copying a param with shape torch.Size([277772, 1]) from checkpoint, the shape in current model is torch.Size([277751, 1]).
The error is pretty, clear, but I don’t know why it is happening, since the dataset is the same. The only steps I take are:
I don’t know.
Potentially you could write a for loop with a try except clause in it and just try out all numbers between 0-100. That would only work if the model was generated with an explicitly set seed though. And obviously the creator didnt choose 193822 to be the random seed