Interesting new paper that uses periodic activation functions (sine) to learn representations of complex signals that are both capable of representing fine detail and preserve spatial and temporal derivatives.
As the official code is not yet released, I implemented it and trained two of the baselines. The first one is a network trained to do image fitting, so it takes coordinates of a pixel and outputs the RGB values correspondent to that pixel. Here is a sample:
Original image from oxford pets:
Output of a SIREN model:
Notice that to create this image I only give the model individual coordinates that span the range of the full image, and it created the pixels one by one.
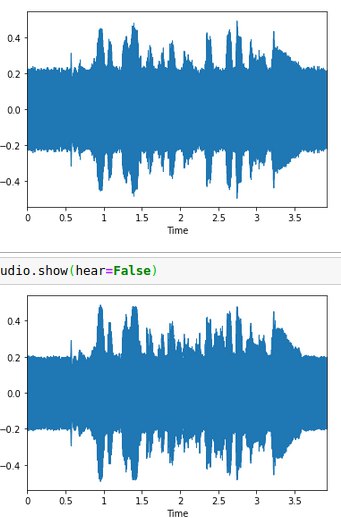
The other baseline that I implemented was audio fitting. It’s very similar to the image fitting, but here the input is the time step and output is the amplitude at that point. Top is from model, bottom is original.
Cool! Could you please show the results you obtained with ReLU as well?
Also, do you think this may be useful for classification or other tasks as well? How can the continuous representations created with such SIREN networks be used for downstream tasks?
I will update the first experiments to compare with a model using ReLU as well.
Regarding the applications of this method, as the representation learned is both continuous and estimates correctly the gradients, it has direct use in engineering and science to solve problems (see this talk for some examples).
For the usual downstream tasks I’m not sure how to apply this model. I tried changing a xResnet architecture to use this activation directly, but the results were not better than the ReLU one (more info). Don’t take this result as conclusive, but rather as a indication that the way I tried to approach the problem was wrong.
So am I understanding correctly that the model acts as a continuous function that maps from coordinates of the image to the color of that pixel? If so does it work for upsampling images to larger sizes and higher resolutions?
Yes , It works for upsampling. The idea will be very similar to the image inpainting experiment, where you fit a number of points then evaluate the network on the missing points
It seems the Siren network is more sensitive to initial parameter chosen, maybe tweaking the Siren parameters will improve its performance in your xResnet classification tasks?



 )
)