Problem:
I want to develop a simple test for detecting out-of-distribution samples (image data) based on the distribution of my training data, prior to training - i.e. to detect and remove outliers from the training data - but probably would like to use it after training as well. One of the reasons I want to do this before training is that my team hasn’t selected a model architecture yet.
Existing solutions (not so simple):
The paper below from NeurIPS 2018 proposed an approach that can be applied to pretrained neural classifiers with softmax output. The paper also references other similar approaches.
However, as I said above, I’d actually like to run something on my training data prior to training to detect outliers within the data itself and determine whether those should be excluded.
Proposed approach:
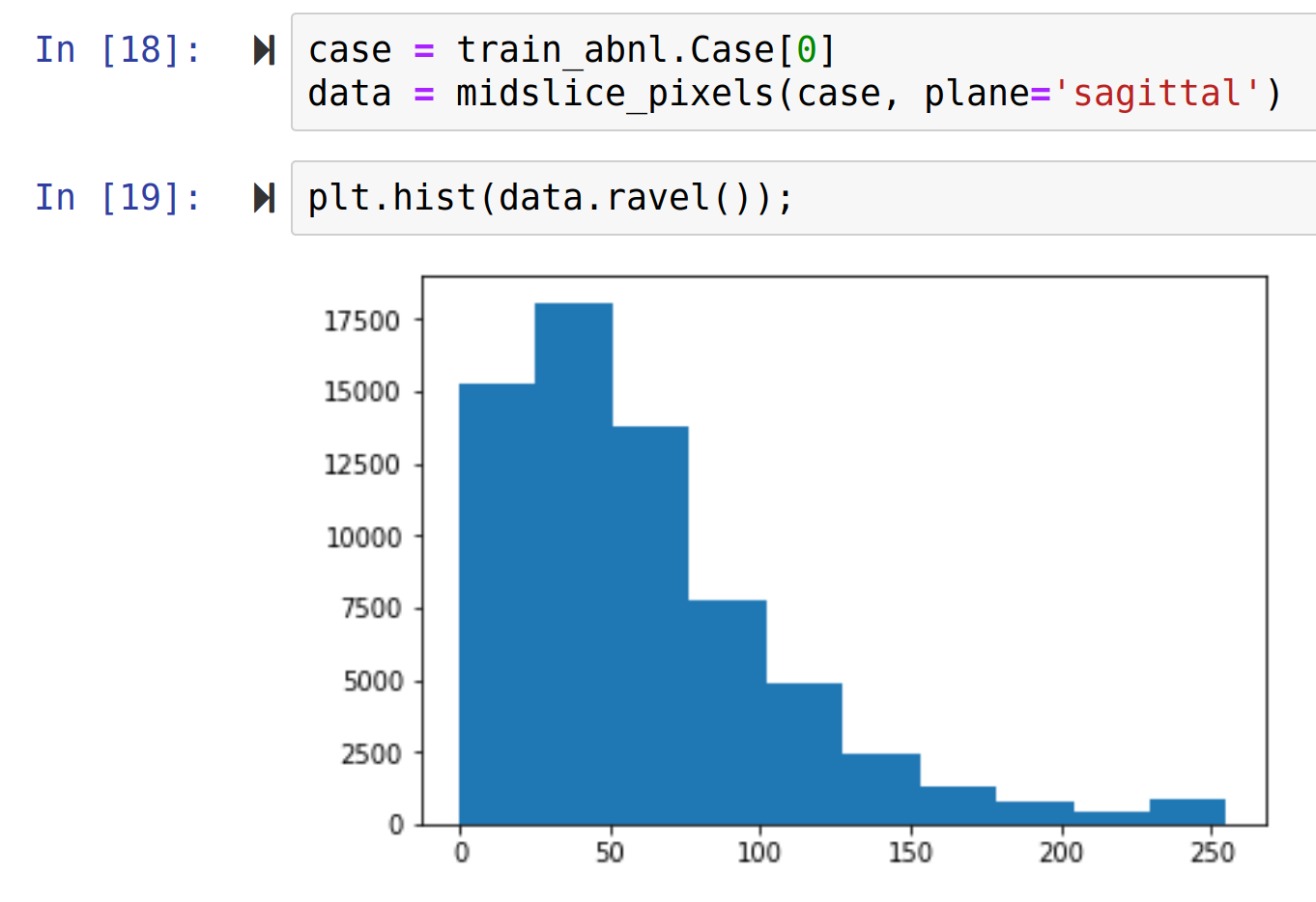
I’m considering experimenting with a two-sample Kolmogorov-Smirnov test, where the first sample is the pixel distribution of a single training sample and the second is some number of manually validated training samples (maybe ~10 to start) from the training data.
Another spin on this approach could be bootstrapping a CDF from the entire training data set and applying a one-sample KS test.
Questions for the group:
Does this approach seem reasonable?
Does anyone else out there have a better approach?
If I understand you correctly when you talk about the ‘pixel distribution’ you mean the per channel intensity histograms?
Do you have a good reason to expect your ‘normal’ images to have a similar intensity histograms (or perhaps one of several characteristic histograms)?
Intensity histograms are a very particular signature of an image. For example the histograms of an image don’t change if you randomly permute the location of pixels. You can shuffle each channel up and you’ll still get the same histograms.
What would the histograms of outliers in your world look like? Are there any outliers you can think of that would have similar histograms to ‘normal’ images.
Alternatively, how about using a pre-trained imagenet network? You could chop off the last few layers. Generate the intermediate features by doing inference on your image set. You could then run a clustering algorithm on the resulting features. Potential outlier images could be those that are distant from any cluster center.
Yes, I’m referring to pixel intensity histograms. Working with grayscale medical image data, so only one channel.
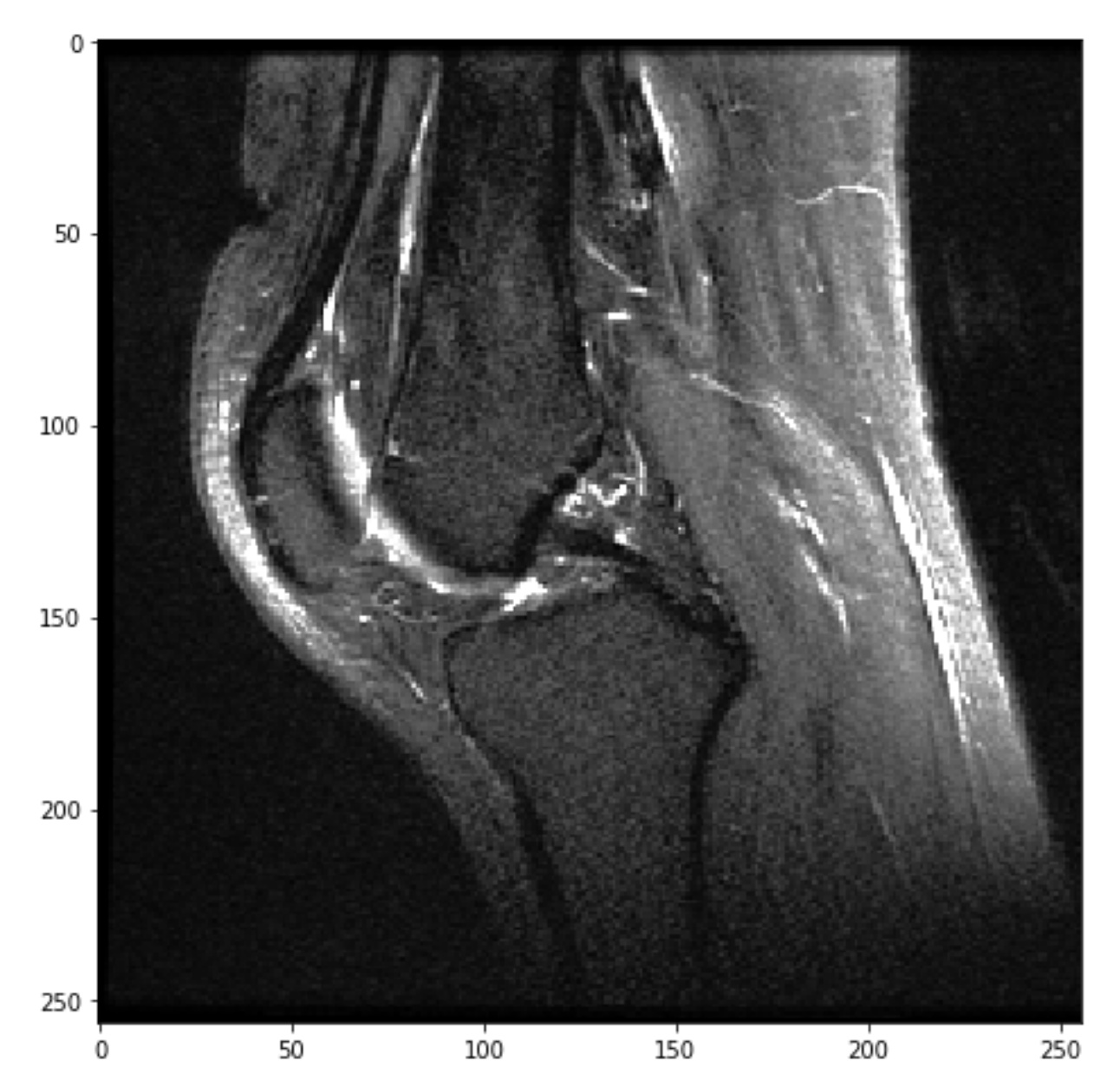
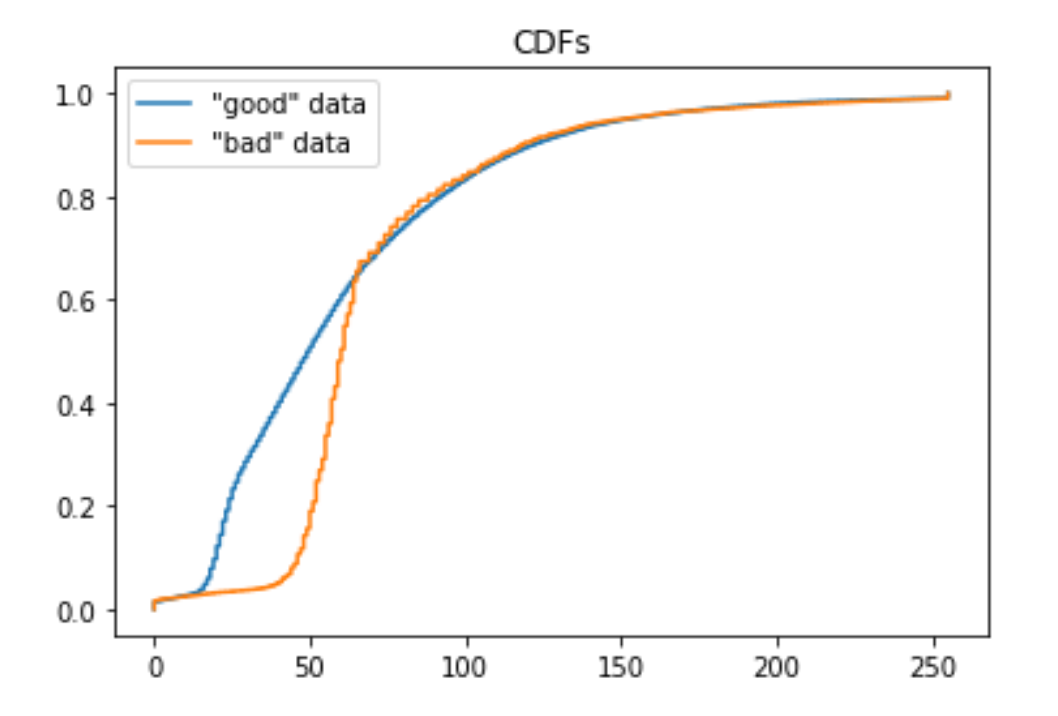
“Good” images should have similar intensity histograms, because they are images of the same anatomy viewed in the same plane. “Bad” images (i.e. the outliers I want to be able to detect and remove) have different intensity histograms because the relevant anatomy is not within the field-of-view. Examples below.
Okay interesting - looking only at monochrome xrays narrows down what is ‘normal’ significantly. If you’re only interested in that specific type of outlier where the relevant anatomy is out of the field of view you may well get away with something even simpler than a KS test. A threshold level for variance might even get you what you’re looking for. If you do go the KS route are you going to normalise the values in any way first - otherwise different levels of exposure will result in a horizontal shift of the histogram?
Are there other types of anomalous data you’re worried about?
Ultimately I think doing some testing of any outlier detection would give you good insight.
I had previously experimented with mean and variance thresholding, which helped a little but wasn’t specific enough.
If you do go the KS route are you going to normalise the values in any way first - otherwise different levels of exposure will result in a horizontal shift of the histogram?
My experiments today with KS testing revealed the need for signal intensity normalization (beyond what was already done by the group that prepared the data set), but this is no simple task in MRI.
Are there other types of anomalous data you’re worried about?
Most anomalous data I actually want to keep. There are only a few cases where I might want to eliminate a sample from the training data.
Ultimately I think doing some testing of any outlier detection would give you good insight.
Right now, thresholding of skewness and kurtosis seems to be the most promising. My AUROC for picking out cases that I might want to exclude from the training data has increased considerably with this approach.