I have a classification NN architecture, it has 3 layers of Dense (keras) with RELU activation then sigmoid. I noticed that sigmoid out on test set is always close to zero ( sigmoid output < 0.2) for every instance in my test set. What can I do for this? THANKS.
May be all your test examples belong to the -ve class? 
OR Maybe your model has overfitted. I can think of the following:
a) Make keras to split your training data into training and validation sets, and track the train/val accuracy for each epoc. Plot it. Make sure there is no large gap between train and val accuracies. E.g. See this link, section “Visualize Model Training History in Keras”
b) Add regularizers
c) Change sigmoid to softmax, what do you get?
-Anand
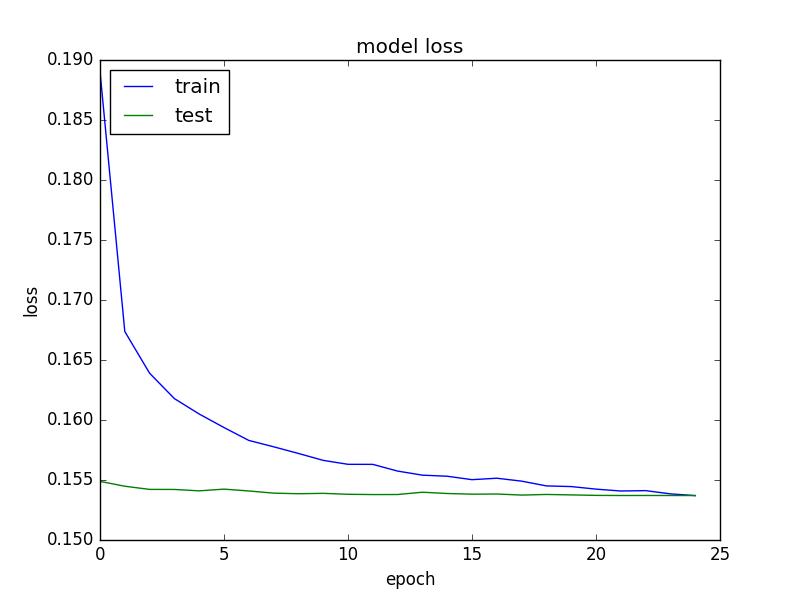
Thanks @anandsaha for your reply. Actually I have these graph as shown below. I’m wondering if RELU is causing the problem or not. I think it is vanishing gradient problem. I have Adam optimizer, which I think would take care of regularization when updating the weights. I will try softmax and will see. Thanks again.
This looks like your training data is not representative of your test data. It could be because your test data is completely different, but one thing to check is that you pre-processed your test data in exactly the same way as your training data (and that your test labels are correct).
@saeed3 I would calculate the a) training set error and b) dev(what you call test) set error.
Then try to figure if you are primarily dealing with high bias, or high variance.
High Bias - Underfitting the data
Training set error is high(~15%), implying the model didnt fit the dataset properly
In add’n if dev set error is much lower (~30%) then model has high bias AND high variance
High Variance - Overfitting the data.
Training set error (~1%) << Dev set error (~11%)
High Bias in the model, try this
Bigger network, more layers, neurons.
Better NN architecture
Train for longer time
High Variance in model, try this
More training examples
Regularization
NN architecture search
PS: These strategies were well discussed in the Coursera DL course Structuring Machine Learning Projects. Here are my Notes from that course and earlier.
2 Likes
What is intriguing is that from 1st epoch itself, his test set loss is much lower than training loss. How is that even possible?
-Anand
I’m unclear on the training and test data graphs too, has it been run simultaneously, or it’s displayed that way. Was the test set run for every epoch, or does it actually refer to validation set.
Could be that there is an imbalance in the count of 0/1 Y output values and the NN has learned to say No(or Yes) every time.
Thanks alot @beecoder, will try bias and variance test.
My data is unbalanced, for “Y” number of cases labeled 0 is 30 * number of cases labeled 1. Data imbalanced could be the issue. Thanks all @beecoder @anandsaha
1 Like