Hello, I am slightly new to using Fastai and would appreciate any thoughts on the implementation below, as I cannot tell if something is wrong with my code/model or if my data just does not have enough predictive potential.
I am trying to model user preferences via a siamese model. Particularly I am using features for user A and user B as input in order to model the distance between their embeddings and predict a binary label of whether they are a good match or not. My code can be found below.
The results are quite odd as I cannot see my accuracy or loss improving (especially on the training set). Basically I cannot get the model to overfit on the training data, it rather fluctuates around a certain value (around 55% accuracy on the validation set and a training loss of 0.7). If I feed the actual label as input the model does pick this up, so I am worried I am doing something wrong on selecting learning rates and a training schedule, although I have tried several combinations.
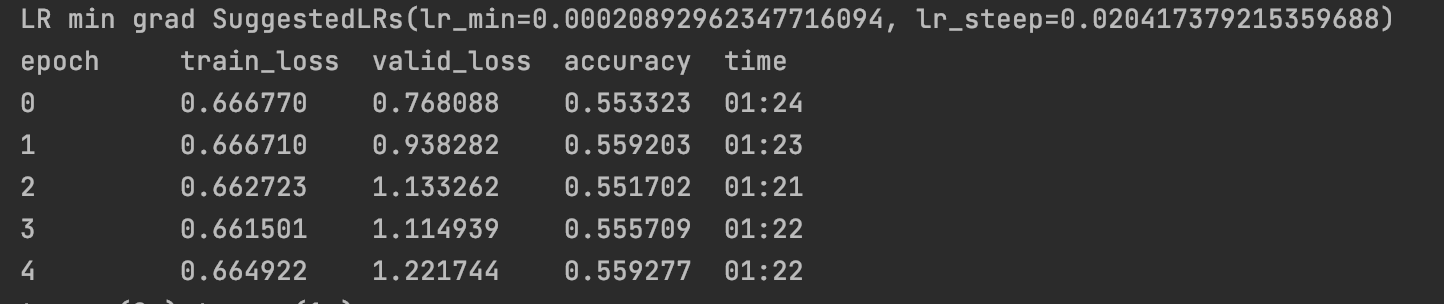
So far I have also tried label smoothing vs regular cross entropy loss, changing the Relu to Sigmoid activations (which has had no effect), playing with learning rates and epochs and scaling the data.
Another odd observation is that when I remove the internal layers of the network (set tabular_config: layers=[]) I do get slightly better results with validation accuracy reaching 60% after a while. I do not know what to make of this.
It is also worth noting that my classes are relatively balanced and that I am getting both classes in my prediction output. My sample size is around 700K examples, I am currently only using continuous variables as features and a batch size of 64.
I would really appreciate any thoughts or advice as well as any feedback regarding how to set the training lr schedule as I assume what I am currently doing is suboptimal.
def build_input_cat_tensor(inp: pd.DataFrame, cat_labels: List[str]):
return torch.tensor(inp.loc[:, cat_labels].values, dtype=torch.int64)
def build_input_cont_tensor(inp: pd.DataFrame, cont_labels: List[str]):
return torch.tensor(inp.loc[:, cont_labels].values, dtype=torch.float)
class SiameseInputSingleSidedDataset(Dataset):
def __init__(
self,
df: pd.DataFrame,
label_col: str,
cat_names: List[str],
cont_names: List[str],
):
self.df = df
self.classes = {col: [0, 1] for col in cat_names}
self.cat_tensor = build_input_cat_tensor(self.df, cat_names)
self.cont_tensor = build_input_cont_tensor(self.df, cont_names)
self.y_tensor = torch.tensor(
self.df.loc[:, label_col].values, dtype=torch.float
)
def __getitem__(self, idx):
left_cats = self.cat_tensor[idx]
left_conts = self.cont_tensor[idx]
y = self.y_tensor[idx]
return tuple((left_cats, left_conts, y))
def __len__(self):
return len(self.df)
class SiameseInputDataset(Dataset):
def __init__(
self,
left: pd.DataFrame,
right: pd.DataFrame,
label_col: str,
cat_names=None,
cont_names=None,
):
self.left, self.right = left, right
self.df_index = self.left.index.values
self.cat_names = cat_names
self.cont_names = cont_names
self.label_col = label_col
self.classes = {col: [0, 1] for col in self.cat_names}
self.y = self.build_labels()
assert np.array_equal(
self.left.index.values, self.right.index.values
), "left and right dataframes have to have the same index"
assert len(left) == len(
right
), "Expecting the two dataframes to have the same length"
self.left_cat_tensor = build_input_cat_tensor(self.left, self.cat_names)
self.left_cont_tensor = build_input_cont_tensor(self.left, self.cont_names)
self.right_cat_tensor = build_input_cat_tensor(self.right, self.cat_names)
self.right_cont_tensor = build_input_cont_tensor(self.right, self.cont_names)
self.y_tensor = torch.tensor(self.y.values, dtype=torch.int)
def __getitem__(self, idx):
left_cats = self.left_cat_tensor[idx]
left_conts = self.left_cont_tensor[idx]
right_cats = self.right_cat_tensor[idx]
right_conts = self.right_cont_tensor[idx]
y = self.y_tensor[idx]
return tuple((left_cats, left_conts, right_cats, right_conts, y))
def __len__(self):
return len(self.left)
def _label(self, idx):
df_index = self.df_index[idx]
left_label = self.left.at[df_index, self.label_col]
right_label = self.right.at[df_index, self.label_col]
assert left_label == right_label, "Label values not aligned!"
if left_label == 1:
return 1.0
else:
return 0.0
def build_labels(self):
labels = pd.Series(index=self.left.index)
labels[
self.left.loc[:, self.label_col] == self.right.loc[:, self.label_col]
] = self.left.loc[:, self.label_col]
labels[self.left.loc[:, self.label_col] > 0.0] = 1.0
return labels
def siamese_dataloader(
left: pd.DataFrame,
right: pd.DataFrame,
label_col: str,
cat_cols=None,
cont_cols=None,
bs=64,
):
input_dataset = SiameseInputDataset(
left, right, label_col=label_col, cat_names=cat_cols, cont_names=cont_cols
)
sampler = BatchSampler(
SequentialSampler(input_dataset), batch_size=bs, drop_last=False
)
# Set batch_size to None to disable automatic batching, we'll handle it with the sampler
dataloader = DataLoader(
input_dataset, batch_size=None, sampler=sampler, batch_sampler=None
)
return dataloader, input_dataset
def siamese_single_sided_dataloader(
left: pd.DataFrame, label_col: str, cat_cols=None, cont_cols=None, bs=64,
):
input_dataset = SiameseInputSingleSidedDataset(
left, label_col=label_col, cat_names=cat_cols, cont_names=cont_cols
)
sampler = BatchSampler(
SequentialSampler(input_dataset), batch_size=bs, drop_last=False
)
# Set batch_size to None to disable automatic batching, we'll handle it with the sampler
dataloader = DataLoader(
input_dataset, batch_size=None, sampler=sampler, batch_sampler=None
)
return dataloader, input_dataset
class SiameseModel(Module):
def __init__(self, emb_szs, n_cont, out_sz, siamese_output_size=1):
self.underlying = self._underlying(emb_szs, n_cont, out_sz)
self.linear = nn.Linear(out_sz * 3, siamese_output_size, bias=True)
self.siamese_output_size = siamese_output_size
def _underlying(self, emb_szs, n_cont, out_sz):
model_config = tabular_config(
emb_szs=emb_szs,
n_cont=n_cont,
out_sz=out_sz,
ps=[0.1, 0.1, 0.1],
embed_p=0.2,
layers=[200, 100],
)
return TabularModel(**model_config)
def forward(self, x1_cat, x1_cont, x2_cat, x2_cont):
first = self.underlying(x1_cat, x1_cont)
second = self.underlying(x2_cat, x2_cont)
distance = first - second
output_raw = self.linear(distance)
return output_raw
if scale:
print("Scaling data")
scaler = StandardScaler().fit(df_1[continuous])
df_1[continuous] = scaler.transform(df_1[continuous])
df_2[continuous] = scaler.transform(df_2[continuous])
print("saving scaler")
dump(scaler, "models/standardScaler.joblib")
training_left = df_1[df_1["last_impression_date"] < "2021-03-15"]
training_right = df_2[df_2["last_impression_date"] < "2021-03-15"]
dataloader, dataset = siamese_dataloader(
training_left, training_right, "label", categorical, continuous, bs=batch_size,
)
print("Num training examples:", len(training_left), len(training_right))
emb_szs = get_emb_sz(dataset, {})
model = SiameseModel(emb_szs, len(continuous), out_sz=100, siamese_output_size=2)
val_left = df_1[(df_1["last_impression_date"] >= "2021-03-15")]
val_right = df_2[(df_2["last_impression_date"] >= "2021-03-15")]
print("Num validation examples:", len(val_left), len(val_right))
valid_dataloader, _ = siamese_dataloader(
val_left, val_right, "label", categorical, continuous, bs=batch_size,
)
dls = DataLoaders(dataloader, valid_dataloader)
learn = Learner(
dls,
model,
metrics=[accuracy],
# loss_func=CrossEntropyLossFlat(),
loss_func=LabelSmoothingCrossEntropy(),
y_block=CategoryBlock(),
)
print(model)
for name, param in model.named_parameters():
if param.requires_grad:
print(name, param.data)
print("fitting")
if plot_lr:
print(
"LR min grad",
learn.lr_find(end_lr=100, num_it=100, show_plot=True, suggestions=True),
)
# prints LR min grad SuggestedLRs(lr_min=0.00020892962347716094, lr_steep=0.020417379215359688)
learn.fit_one_cycle(5, max_lr=0.020417379215359688)