The Kaggle’s Quora Pairs competition’s objective is to figure out if 2 questions have the same meaning. This should help users find similar questions and reduce duplicate content on Quora.
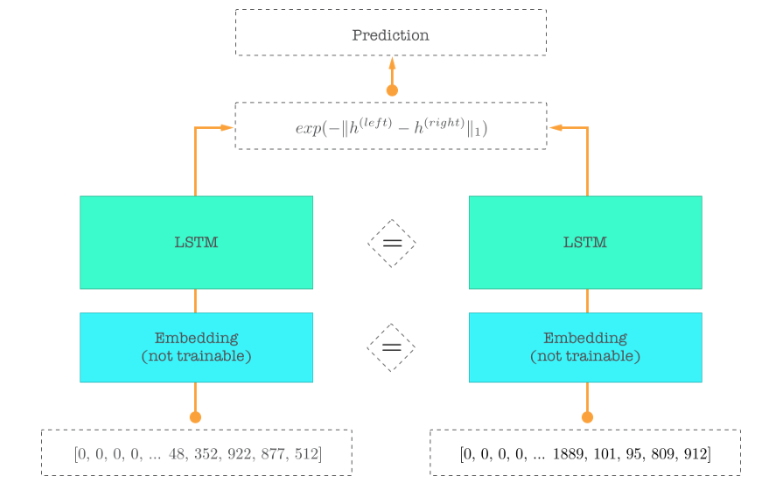
One solution could to be create a language model using the dataset. And then forming a Siamese Network (reference to Siamese twins, image below from Medium article) that takes in 2 questions and compares the output activations using cross entropy (or Manhattan distance).
How can this Siamese network architecture be implemented using the fast.ai library.
I have trained the language model on the Quora dataset.
Would I need to implement this architecture in PyTorch, or can I use some fast.ai modules to create this architecture.
This is as far as i got to a fully working model. I can’t seem to get the same accuracy as stated in the blog post. I must have missed something out in my implementation. Feel free to run it and see if it works for you dataset.
It’s pretty close! One thing they do in the blog post is to freeze the weights on the embeddings - have you done that? Are you using the same optim and hyperparams? Have you checked whether your weight initialization is the same?
@jeremy In my case, I didn’t use any pretrained embeddings. After training around 10 epochs while decreasing the learning rates, I got around 82.8% which is more or less the same results. Thanks! Really enjoying pytorch so far.