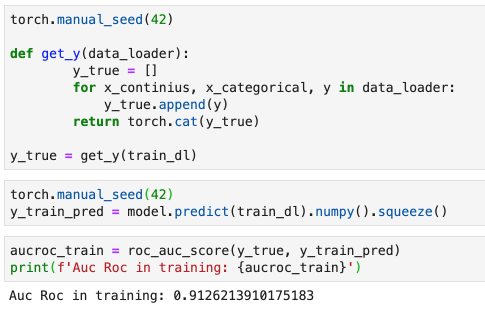
Hi,
I’m playing with de Adults Dataset (UCI Repository), and I’m experiencing something I don’t have an explanation about it
This is my model
class UciAdultsClassifier(nn.Module):
def __init__(self, q_continius_features:int, q_categorical_features:int, embedding_dims:list):
super(UciAdultsClassifier, self).__init__()
embedding_sizes = sum([embedding_size for _, embedding_size in embedding_dims])
self.embeddings_layer=nn.ModuleList(
[nn.Embedding(vocabulary_size, embedding_size) for vocabulary_size, embedding_size in embedding_dims]
)
self.embedding_dropout = nn.Dropout(0.6)
self.layer1=nn.Sequential(
nn.Linear(embedding_sizes + q_continius_features, 128),
nn.ReLU(),
nn.BatchNorm1d(128),
)
self.layer2=nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(0.3),
nn.BatchNorm1d(64),
)
self.layer3=nn.Sequential(
nn.Linear(64, 32),
nn.ReLU(),
nn.Dropout(0.3),
nn.BatchNorm1d(32),
)
self.output=nn.Sequential(
nn.Linear(32, 1),
nn.ReLU(),
nn.Dropout(0.3),
nn.BatchNorm1d(1),
nn.Sigmoid()
)
def forward(self, continius_features, categorical_features):
embeds = [emb_layer(categorical_features[:, i]) for i, emb_layer in enumerate(self.embeddings_layer)]
embeds = torch.cat(embeds, 1)
x = self.embedding_dropout(embeds)
x = torch.cat([embeds, continius_features], 1)
x = self.layer1(torch.cat([embeds, continius_features], 1))
x = self.layer2(x)
x = self.layer3(x)
return self.output(x)
def fit(self, train_dl:DataLoader, epochs:int, opt:Optimizer, loss_fn:any) -> list:
self.train()
losses = []
for i in range(epochs):
for x_continius, x_categorical, y in train_dl:
y_pred = self.forward(x_continius, x_categorical)
loss = loss_fn(y_pred, y)
losses.append(loss.item())
loss.backward()
opt.step()
opt.zero_grad()
return losses
def predict(self, data_loader:DataLoader) -> torch.Tensor:
self.eval()
predictions = []
with torch.no_grad():
for x_continius, x_categorical, y in data_loader:
preds = self.forward(x_continius, x_categorical)
predictions.append(preds)
return torch.cat(predictions)
My Dataloaders
train_dl = DataLoader(train_ds, batch_size=1000, shuffle=False)
test_dl = DataLoader(test_ds, batch_size=1000, shuffle=False)
My settings:
model = UciAdultsClassifier(q_continius_features=q_continius_columns, q_categorical_features=q_categorical_columns, embedding_dims=embedding_dims)
optimizer = optim.Adam(model.parameters(), lr=1e-2)
bceloss_fn = nn.BCELoss(reduction='mean')
epochs=100
losses = model.fit(train_dl=train_dl, epochs=epochs, loss_fn=bceloss_fn, opt=optimizer)
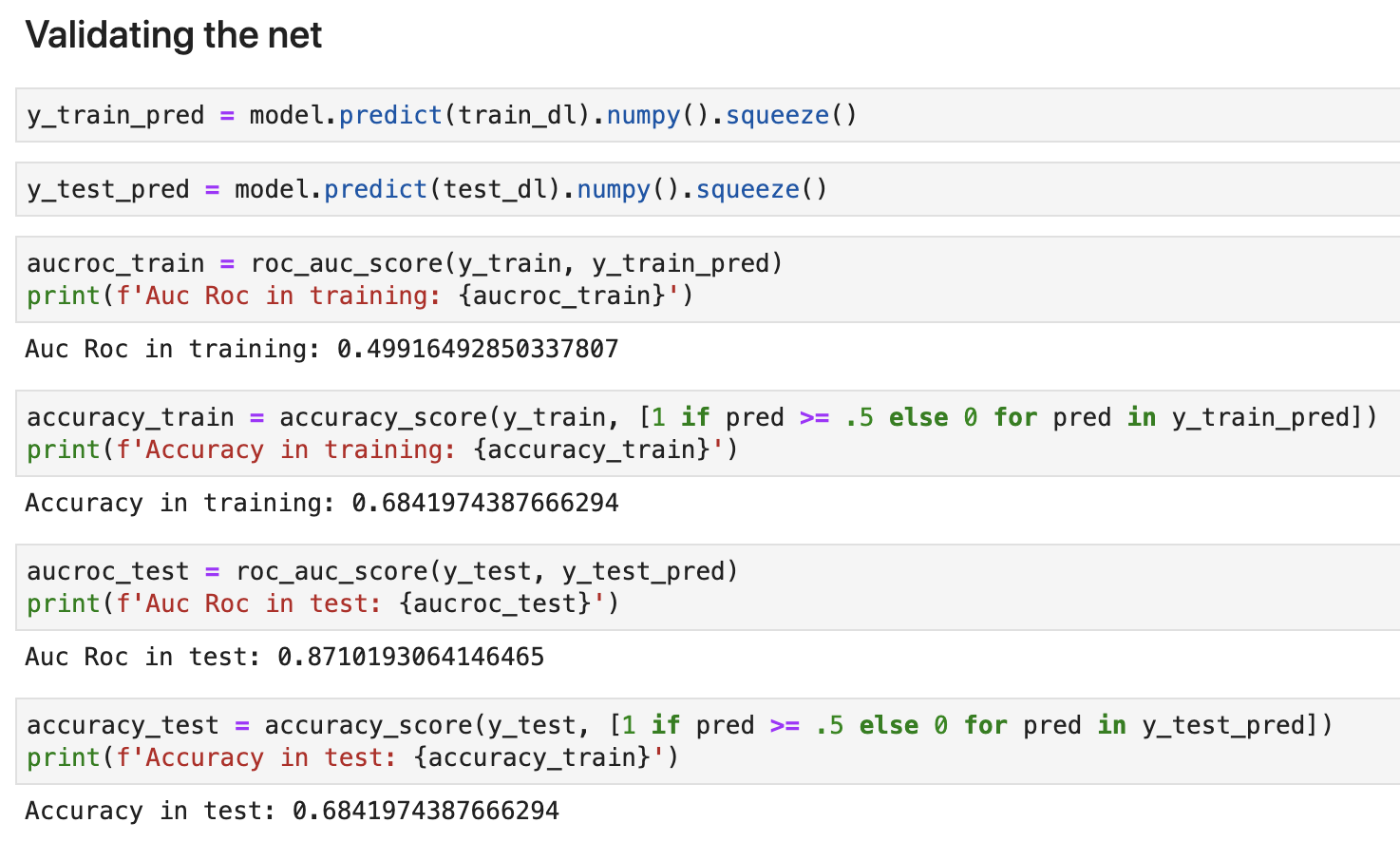
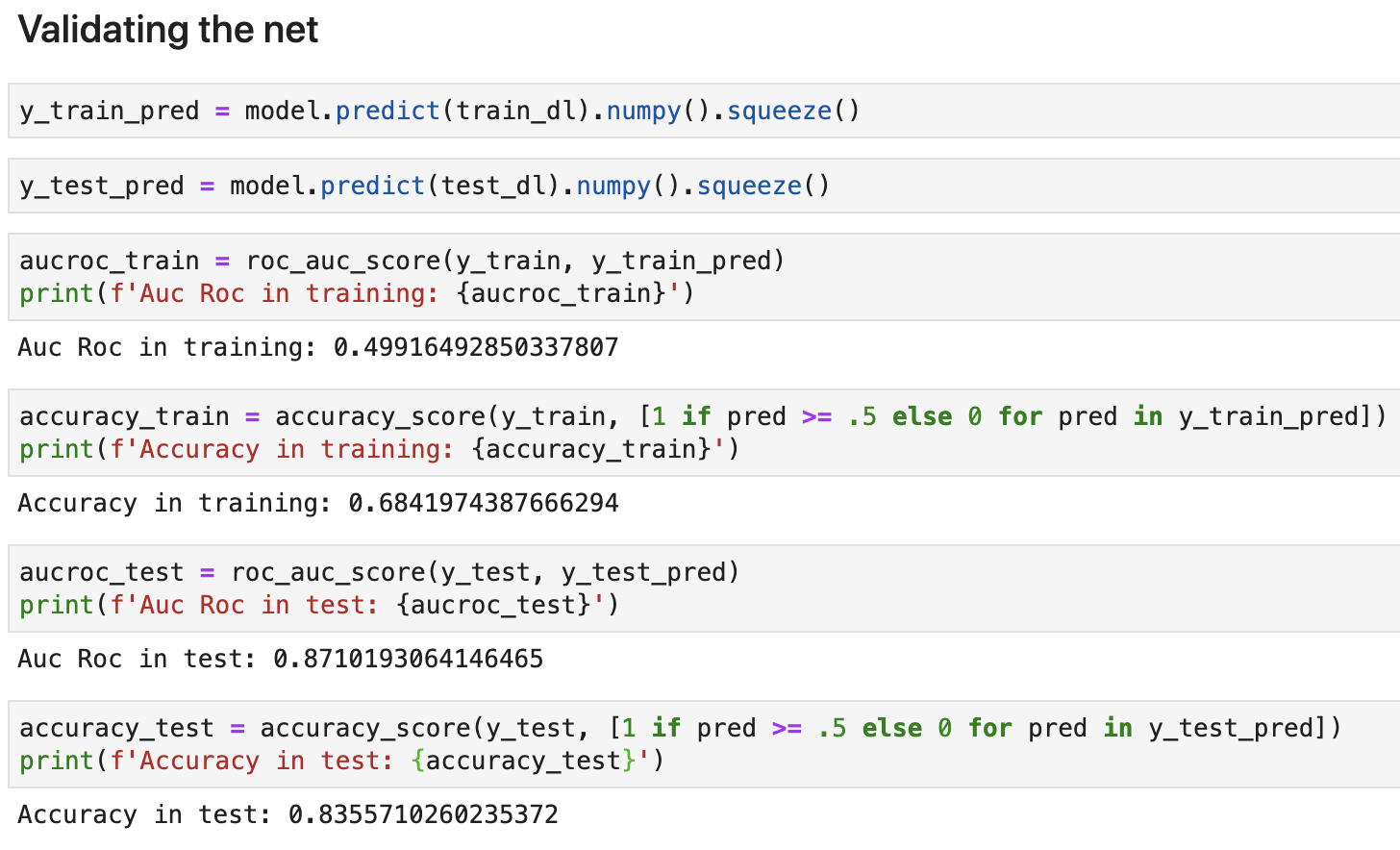
My metrics
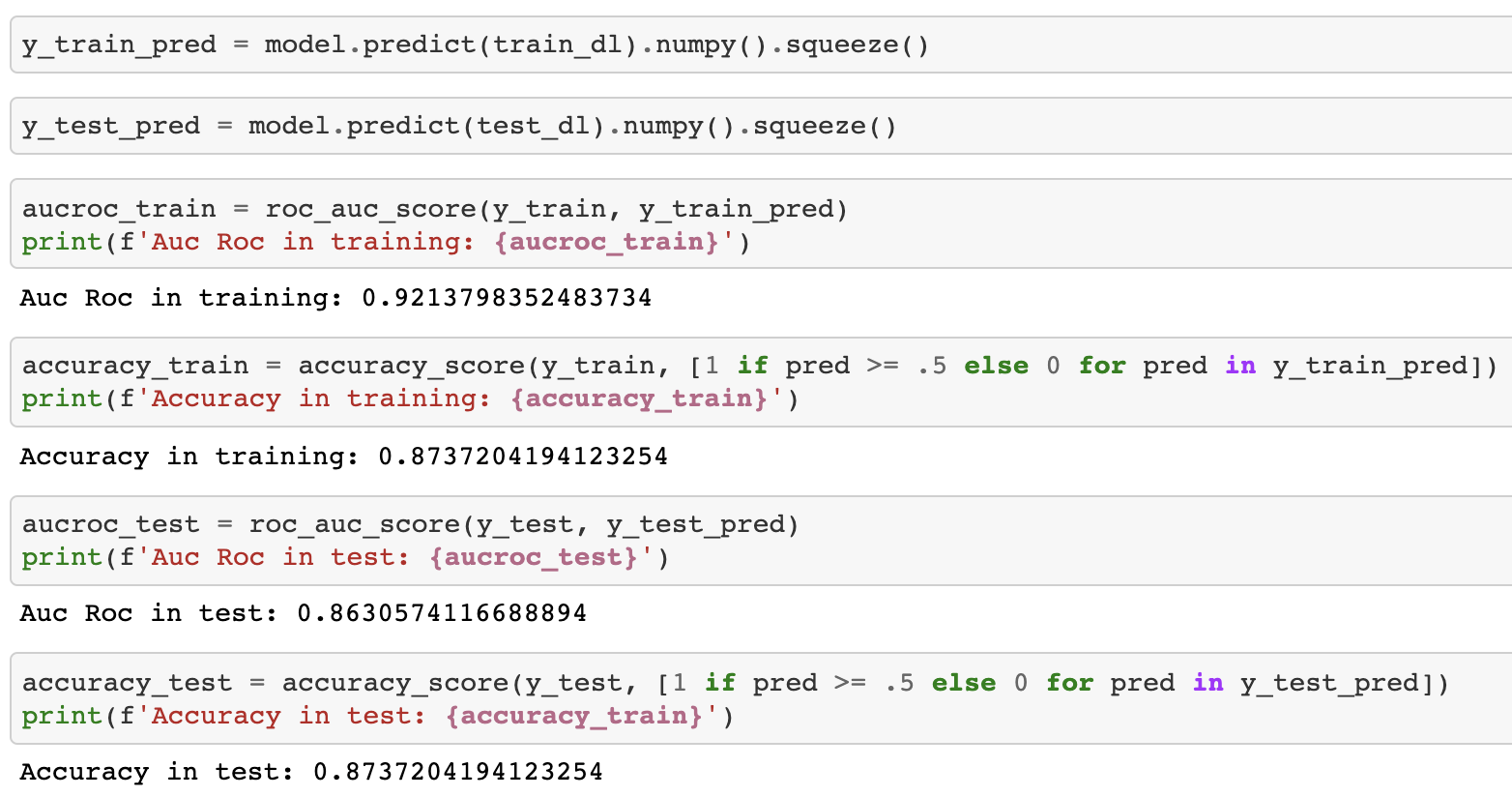
When I change the Dataloader to this line (shuffle=True)
train_dl = DataLoader(train_ds, batch_size=1000, shuffle=True)
test_dl = DataLoader(test_ds, batch_size=1000, shuffle=False)
My training Auc Roc falls down to 50%
Why is this happening? Let me know if you want to check de NB.
Best regards
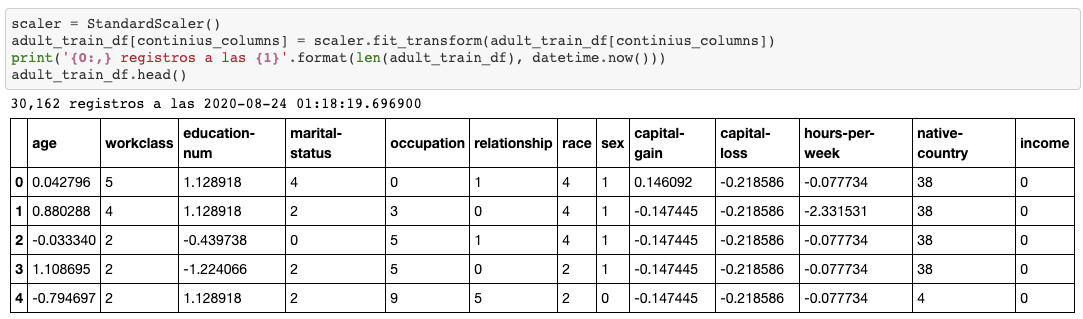
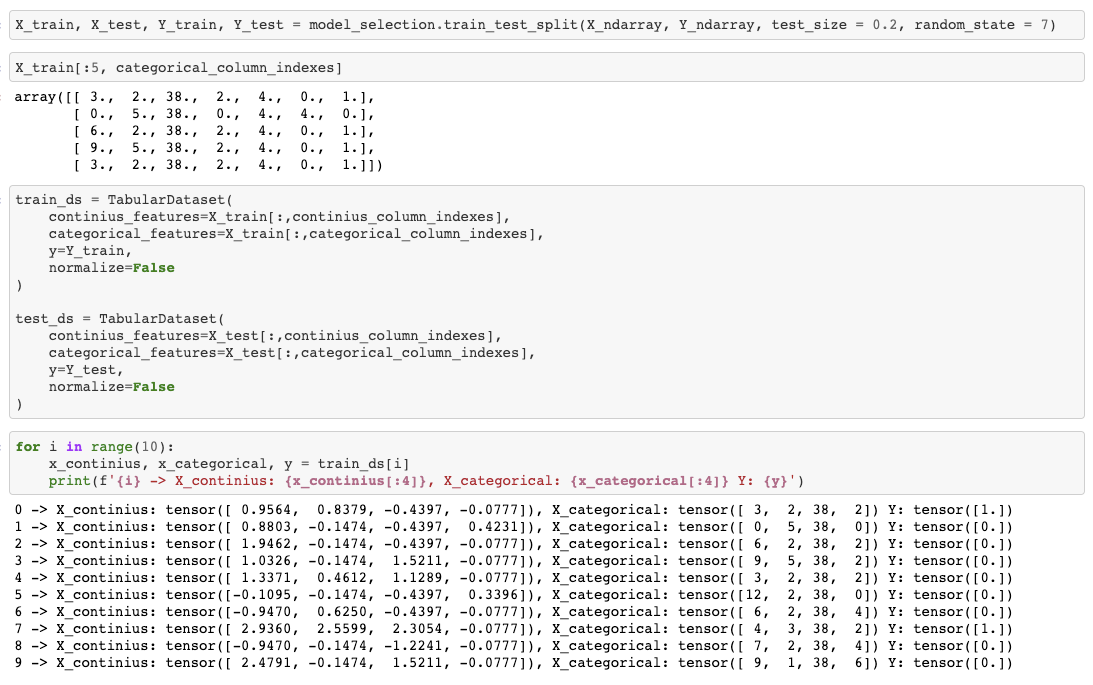
 (also not sure if y_train you compare with is somehow different from Y_train create on split)
(also not sure if y_train you compare with is somehow different from Y_train create on split)