My question is, if I should retrained my final model on the full available data set (train+validation, not test) after the validation step(s)?
And if yes, when should I choose to stop? (epoch? loss? etc.)
How do you usually proceed after finding the “best” architecture (+ after hyperparameter tuning) for your task, if you want to use your system?
Hi,
Usually, to verify your choice of an NN architecture, you separate 10% of the training data as the hold-out validation set to run an early study on various deep-learning network architectures. After finding the optimal architecture on this validation set, training is repeated on the entire training set. Finally, you evaluate the newly trained model on your test set.
I already have my train, validation and test set separated. I never use the test set to train/adapt my system, but I use the validation set to “test” during training. After finding my final “best” architecture, I was wondering if I should use train+validation sets for a final training of my model and if doing so when to stop the learning procedure (which epoch? loss? etc.).
The reason for the question is that I know when to stop during the training phase, which I do while looking at the loss on the validation set. Does this makes any sense to you?
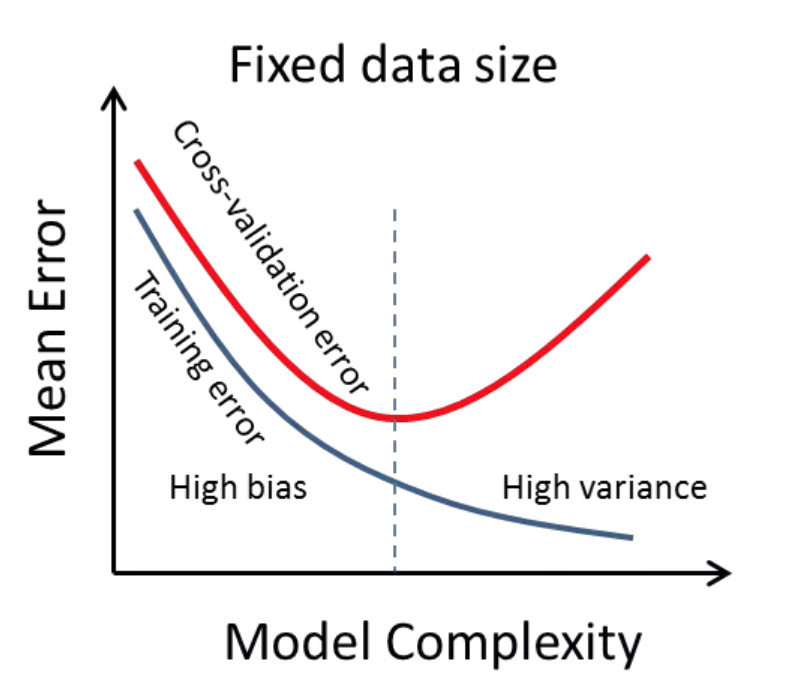
Maybe the picture bellow makes it a little bit clearer.
I was inspired by the question to tweet about this
The short answer is that it is always dangerous to mess with training on anything but the train set. There is a bit of math theory that one might be inclined to read about - the Hoeffding bound, VC dimensions, etc if one really, really wants to get to the bottom of this. This is nicely covered in the edx MOOC Learning from Data Approach with caution as it is not very practical.
There is this interesting passage in a paper by Ian Goodfellow et al. that I found that is relevant:
One has to be cautious though to not overfit. And never ever touch the test set or at least never show your model the objective labels on it during training to be more precise
I think you have the right idea here regarding never using the test set for feedback and only testing on the final model once. Training on the full data before deployment should help squeeze out just a little more accuracy/auc from the data, which I think is what you’re aiming for
Make sure that both the validation and test sets come from the same real world distribution the model will be deployed on - this would minimise any surprises during the final test
For traditional machine learning, it’s easy to retrain with the same hyperparameters as we’re starting from scratch but is relatively more fuzzy for neural network. If your model took a long time to train, it may be wiser to not retrain but if it converged really fast, then I would retrain from scratch on the full data with exactly the same hyperparameters (including the number of epochs)
Do note that all this is only useful in use cases where we don’t have big data sizes as there won’t be a difference between weights learnt from 1 million images vs 1.05 million - which is the ideal train-validation split for big data sizes
IMHO, The purpose of the CV pipeline is to significantly enhance the reliability of the system aiming at a validation log loss score which is consistently lower than the training log loss. The training set sampling should be stratified such that a near-50/50-distribution between the labels. Finally, To assess the confidence interval of the area under the ROC curve, I suggest you use bootstrapping using N (depending on your data set) bootstrap samples.
Notwithstanding, for cross-validation purposes, once you finish training you can use the following advanced technique:
Using the final model, you label the TEST set as if your model is always right.
Then you train on the TEST set and infer on the TRAIN set.
You then compare the CV scores; ideally, they should be similar.
@dtrtrtm How did you treat your validation data after you got your final model now? I didn’t think your problems were solved in this discussion.
I have the same question as you had. When we train NN model, validation set is a kind of guide for our training process. If we retrain our model with train+validation data, how to guide our training process, such as when we will stop training. Another question is we will retrain our final model from scratch or continue training a couple of epochs using train+validation data?
Please share your thoughts if you have a satisfying solution. Many thanks.
From Ian Goodfellow’s paper, I don’t know how to get the validation set log-likelihood when we trained on the full 60,000 examples. Because, at this stage, the validation dataset didn’t exist anymore. If we still use the previews validation dataset, the validation loss will be very small because the validation dataset is already in the training set. Any thoughts about this? Thanks