I meant a random scalar that’s broadcast to the entire layer, as opposed to creating random tensors and element wise subtraction.
I’m still unsure I follow. Do you mean to subtract a different value for each layer, or for each training event? Or something else I am not understanding?
Subtract a different value for each layer instead of 0.5 every time. Like this:
y = y.clamp(min=0) - torch.rand(1)/2
If you implement it like that, wouldn’t it use a different value every iteration? I guess you would need to define the value at init.
In any case, subtracting 0.5 was motivated by the fact that ReLU biases activations towards positive values, and results seem to agree that this takes the average activation back to around 0. Using random values between 0 and 0.5 would result in an intermediate situation, right? I don’t see how that should be better. Of course, the ultimate answer is to try things out and see!
Since the mean is 0 and stddev is 1, a large number of inputs would be clustered around 0. As we move towards 1 or -1 there would be fewer and fewer values. Relu brutally chops of ~50% of them. Then we try to offset the rest by 0.5 to compensate the shift in the mean.
But 0.5 is a huge value in this regime of unit normal. Hence a milder shift seemed like a good idea.
Also, wanted to keep the number deliberately random each layer( and as a result each training loop ) to see if the model manages to converge. Well, if it can withstand a dropout, it probably can withstand a random relu shift. Let’s see…
But yes, lot of experiments are required. I’ll try to find time once I reach home.
1 Like
Why do this?
Not exactly sure how a network with train with this… sometimes your weights are positive and sometimes they are negative, based completely on a random number. Dropout works because of the special case of 0 meaning the weight doesn’t contribute at all. In your example the network would somehow have to be sign agnostic, which seems to be outside of what we can represent mathematically.
High weight * positive number = high positive activation
High weight * negative number = high negative activation
These have exact opposite representations in a neural net.
No matter how I look at it I kind of feel like this should be a normal distribution, and we should basically apply batchnorm to get something close.
I was going to comment the same, I don’t understand the intuition of shifting ReLU because if we have a symmetrical distribution with mean 0 and standard deviation 1, after the ReLU we are making all the negatives 0 so the distribution is no longer symmetric and has about half of the values equal to 0. If we then apply a convolution the dot product will “ignore” the places where the activation is 0. If on the other hand we have -0.5 instead of 0 all these values will have an identical contribution to the dot product and I’m not sure if that is desirable.
Try it and see! ![]()
1 Like
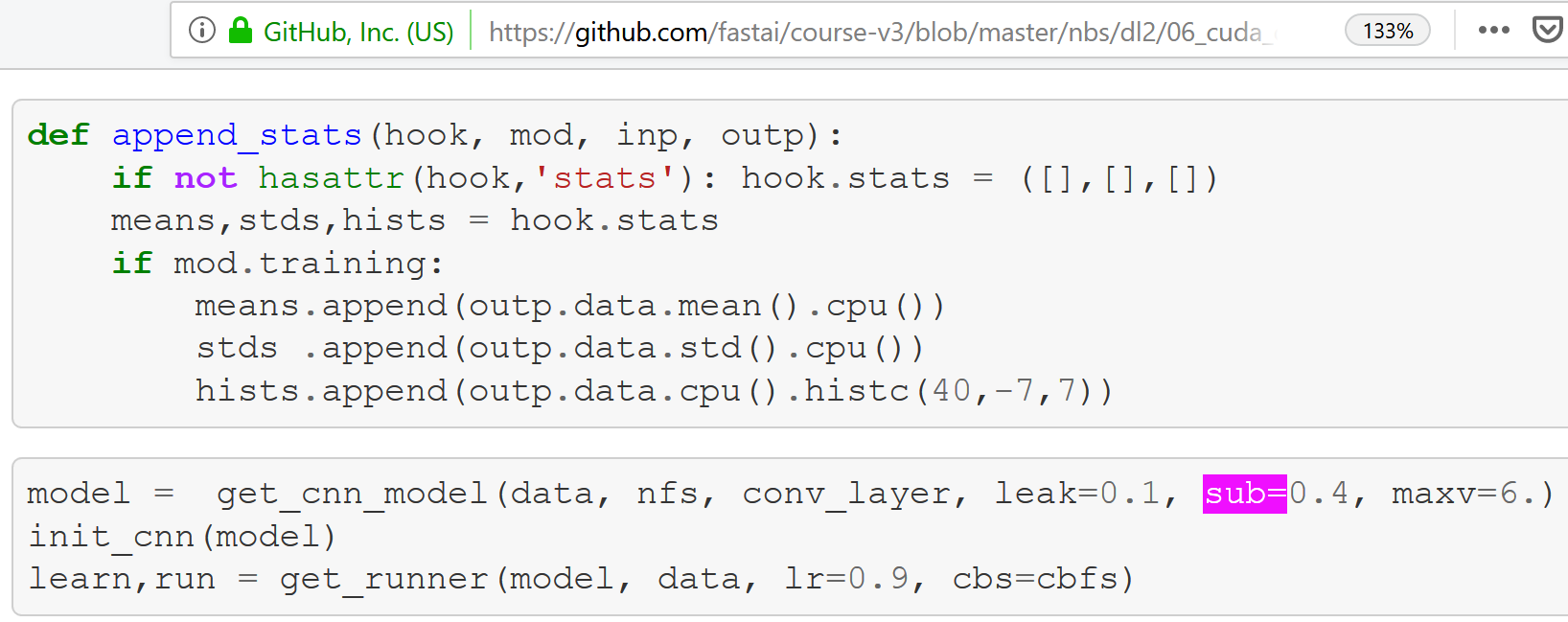
An array that started with mean 0 and got relu’d doesn’t have mean 0.5. It would, if you just deleted the negative values, but since you clamp them all to 0, you pull the mean towards 0. A quick experiment indicates the mean in this case is 0.4. I doubt that 0.1 difference is gonna change our results much, but based on the logic of correcting the mean to 0, it looks like -0.4 might make a little more sense than -0.5.
looks like you are looking for torch.nn.SELU
Hmm, I’m not sure I follow. As far as I can tell, SELU is sort of a fancier leaky ReLU. My point was just that if you want to restore the mean to 0 after applying a vanilla ReLU, ala Jeremy’s suggestion, I think -0.4 might work a little better than -0.5. But I’m probably missing something