There are a lot of unanswered questions, here on the forum, about almost every aspect related to the LR and its management in fastai.
Let’s start talking about the 1-cycle scheduler, which appears to be the most effective scheduling policy when it comes to LR management.
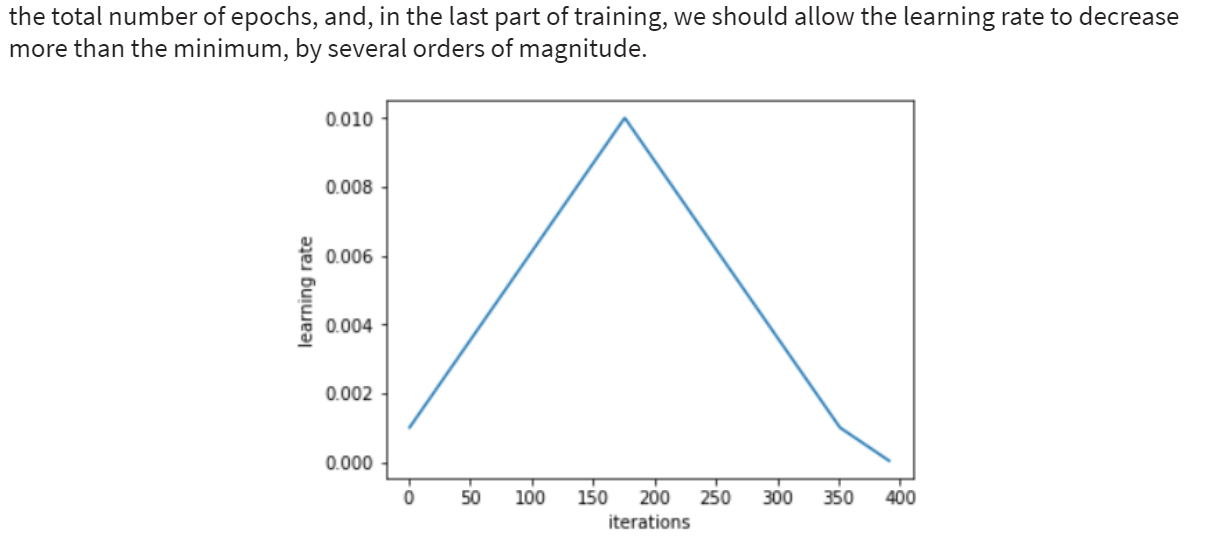
As Sylvain Gugger explains in his epic summary of Smith’s papers, one should do a few epochs at the end of the cycle, allowing the LR to go well below the minimum (which, by default, is 1/25 of the maximum in fastai), for the last few epochs. This allows us to go deeper in the minimum we got ourselves into.
AFAIK (and after a quick search) no one ever asked how to set this.
But then I noticed there is a promising final_div argument for the OneCycleScheduler callback.
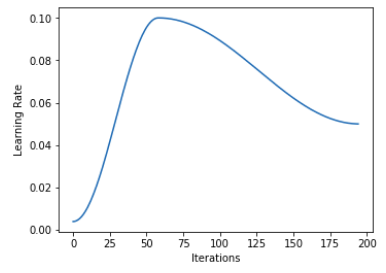
And indeed it seems it should do the trick. But then, if you call learn.recorder.plot_lr() you can observe that the final epochs are performed with a LR well below the minimum even if you leave final_div to its default None. As a matter of fact, I noticed that the plot is the same no matter how you set final_div
Another interesting thing would be to set the length of these final epochs.
Question 1a: How can I set the LR for the final part?
Question 1b: How I can set the length of the final part?
Let’s talk a bit about pct_start. Smith suggests to spend more or less the same number of epochs both for the ascending and the descending part of the cycle. Still, we have a default of 0.3 for pct_start.
Question 2: Why did you choose to do fewer epochs for the ascending part? Furthermore, can you mention some cases when it would be advisable to do the contrary? E.g. here and there over the notebooks you do 0.1 or 0.9, but I was unable to catch a pattern of usage.
Now, regarding the other stuff. We can pass a slice to fit_one_cycle(), or we can pass max_lr=X, or we can even pass max_lr=slice(X,Y).
As far as I understand, there is no point in passing a slice unless we are working upon an unfrozen model. That is, slice(X,Y) sets the maximum LR to X for the early group, Y for the last group, and something in the middle for the central group (is this correct?).
max_lr, on the other hand, makes me scratch my head. The maximum LR should be the value we pass directly to fit_one_cycle(). That is, a call to fit_one_cycle(10, 1e-3) should be exactly the same asfit_one_cycle(10, max_lr=1e-3). So max_lr seems to be completely pointless.
Question 3: how does one make use of max_lr?
Last but not least: how to construe a plot like this:
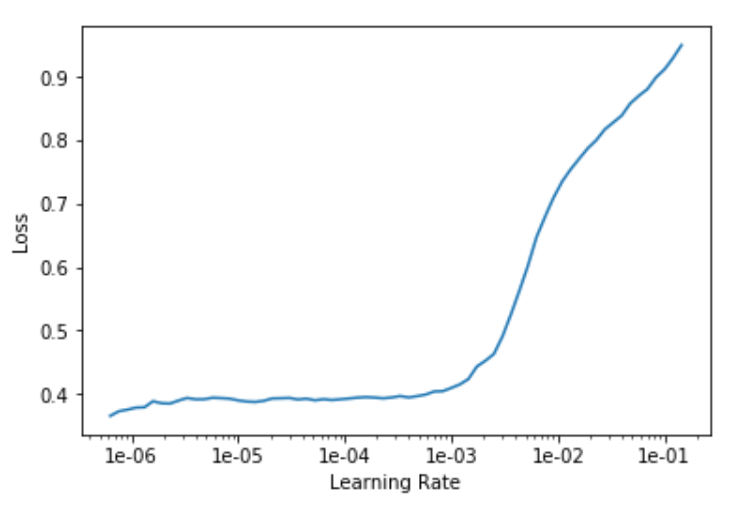
Such a monstrosity comes from lesson 3 (segmentation).
As you may see, we don’t have any segment of negative slope (apart from a slight hint of it around 1e-5). Here is what Jeremy did:
lrs = slice(1e-5,lr/5)
lr here was 1e-2. So, surprisingly enough, he is selecting 2e-3 as his maximum LR, and you can clearly see that at that point the loss is already starting to badly blow up.
That’s all. Thanks!