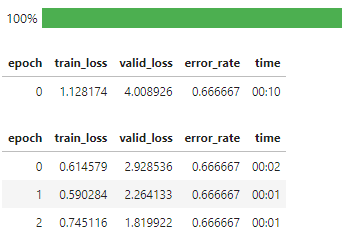
Just sharing Interstellar, my first visual learner (after lesson 2) to classify images of astronomical objects using ResNet50 and transfer learning (1 + 3 epochs).
The object model (accuracy 91.7%) classifies an image into an specific astronomy object.
The datasets have been created using Bing Search API.
Future work:
Discriminate non-astronomical images.
Research whether it would be possible to train a single model such that it can classify an image under an astronomy class, while attempting to recognize a specific object (instead of training a model for each task).
First of all thanks so much for setting up this course!
I completed the first lesson I and trained a model that can classify chords written in sheet music as major or minor, with 100% (for my own curated dataset). One caveat is that the dataset is very clean, so heavily biased to a specific template format which applies to all the images. I imagine I’d have to extend my dataset much more to make this model application more useful.
That said, the purpose of this task was to learn a bit more about deep learning and I’m very proud I managed to do it.
I made tried making an image classifier that would predict what type of climate a landscape photo was. At best, the model got 43% error rate (57% accuracy). After seeing some of the images that were collected from duckduckgo, it is clear that the data could use some tidying up and it might also be that some types of climate look very similar in general.
Another thing is that I am auditing this course in Feb 2024 and ddg_images has been deprecated. For anyone auditing the course now, there is a StackOverflow page about how to get it up and running again with the latest code from the duckduckgo_search documentation. I also included a note about it in my notebook too in case anyone wants to check it out! Happy coding everyone!
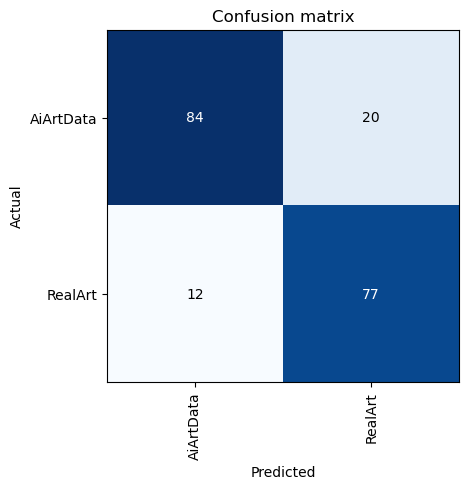
Started the course again, so here is another entry in this thread! This time I classified real image and ai generated images using this dataset. Initially my model was better at predicting AI images than real ones, but after dataset cleaning technique Jeremy mentioned, the model got much better. Here is the ipydb file for the model, and here is a huggingface space for the detection process.
As the confusion matrix (and the fact that if I upload my own image to the space, the model thinks its AI generated) suggests the model can be lot better, and I hope I can improve it throughout the course!
Well, I tried to teach my computer how to identify the different races from D&D 5.0. I had decent success, 1600 images:
Sadly, I could never get it to beat the 81% accuracy mark off the data I had. Considering having only 500 images and using the resnet18 yielded 78% success, all the extra time in using a more recent resnet and increasing the images to 1600 only gained me 3%. Hopefully, later sections get me farther
Multi-Layer Perceptron to Classify Handwritten Digits (0-9)
As further research for Lesson 3, I implemented from scratch a model and learner (incl. linear layer, ReLU, sequential layer, flatten layer, and optimizer) to classify handwritten digits (0-9) from the full MNIST dataset. This allowed me to test different model architectures and to intentionally break the model by e.g. not flattening the input, removing non-linearity, and initializing weights and biases to the same value.
The best results (95.5% accuracy) were obtained by sequentially combining a flattening layer, three linear layers ((128, 64) hidden dimensions) and ReLUs, with 15 training epochs and a batch size = 64 . Training and Test MNIST datasets are loaded with PyTorch dataloaders.
Learning Notes
Weights and biases need to be registered in PyTorch. This allows the optimizer, which takes a list of parameters as input, to update those parameter values during backpropagation.
The output type of the model needs to match the input type of the loss function. In this case, CrossEntropyLoss expects logits as input, and then it applies the softmax function internally to infer the probabilities of each class.
Random initialization of model parameters matters. By implementing a linear function from scratch, I could test that initializing all the parameters to the same value (e.g., zero) makes all units symmetric (this results in practice in all parameters being updated by the same value during backpropagation). This results, as expected, in poor performance and no learning during training.
Removing non-linear activation layers prevented the model from learning after a low number of epochs. As expected, ReLUs indeed help the model learn more complex patterns.
While the choice of hidden dimensions did not appear to have a big effect on the accuracy of the model, a smaller batch size (64) yielded better results.
A couple of days ago I started part 1 classes and it is becoming very bearable for me despite not having great knowledge in mathematics.
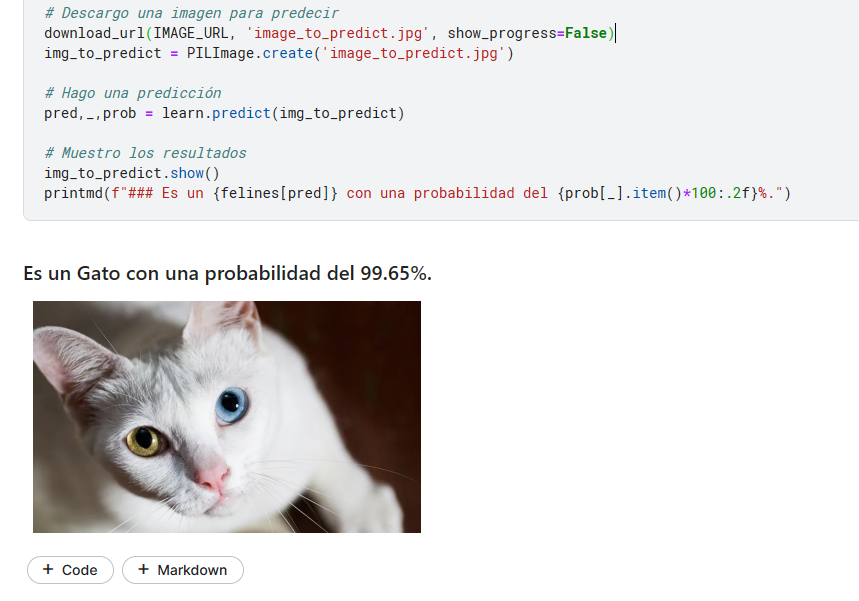
At the moment I have made a Feline Classifier. Specifically, it allows you to classify images of: cats, lions, tigers, leopards, cheetahs and lynxes.
Some observations to keep in mind:
Change some search terms to avoid downloading the wrong images. Example: find a leopard and get a tank haha.
For some categories I use more than one search term. Example: male and female lions, since they are very different.
Differentiating leopards from cheetahs is a bit difficult, both are spotted. Try adding some search terms to get photos of their faces (cheetahs have two black lines under their eyes) and their full body (cheetahs are less stocky).
Possibly some more terms should be added to improve precision in cases but I didn’t want to make it too complex now. Example: white lions, Egyptian cats, Bengal cats, etc.
I trained a model to categorize whether a listing for a subleasing website had professional or unprofessional photos uploaded by the users. Here’s a screenshot!
Following in a seemingly long line of fast.ai students who are also Silicon Valley fans, I attempted to create Jian Yang’s Hotdog or Not Hotdog app for this assignment.
It worked out pretty well, but my classifier flipped things and tried to classify whether or not the image was not a hotdog (i.e. my other category “dinner”) and I couldn’t figure out how to tell the classifier which label was the target.
Does anyone know how to set that in the DataBlock (assuming that’s the place to do it)? My hunch is that it defaults to the alphabetical first category (birds/forest, dinner/hotdog) but I’m just guessing.
Regardless, since I only had 2 categories it was easy enough to convert things to the probability of my image being a hotdog (1 - P_not_hotdot):
I decided to ditch the whole gradio thing and go crazy with an inference api + discord.py bot
Only took me a day, but it’s satisfying and my friends can use it easily
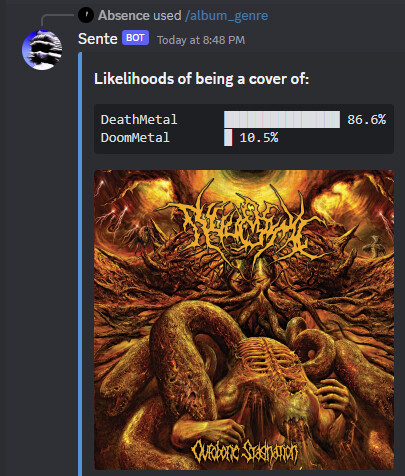
This is a resnet34 finetune to assign a music genre as if an image that is passed a album cover
This is not a classifier per se. Well, it functions like one, but it’s obviously impossible to determine a music genre from a cover image, since there are no standards on how covers should like. But, it is still usable in a sense that it decently catches the general vibe, since it knows how a typical Death Metal cover would look like.
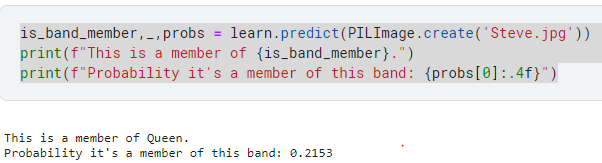
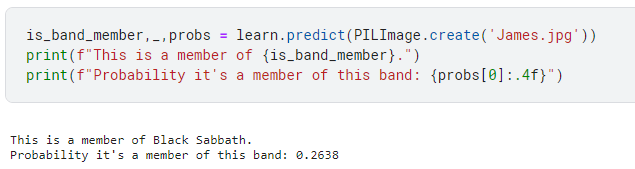
So lets upload an image of me, see which band I would be in:
Unable to show anymore, but I was defined as a member of Queen.
I then used an image of James Hetfield from Metallica and he was defined as a member of Black Sabbath. Her was wearing a lot of black in the image I used.
A simple terrain recognition that i did to cement the lesson for lesson one and two
The notebook: terrain | Kaggle
hugging face space: Terrain - a Hugging Face Space by Mekbib
I tried using the gradio api to create a web interface but it wasn’t working quite well so i just embeded the hugging face space on my page: Terrain recognition