Always welcome
1 Like
Hi all,
Really enjoying the course (only done 2 weeks so far). Even managed to create a chicken breed predictor with a high accuracy using a dataset from Kaggle!
I’ve integrated it into a hugging faces space and I’ve got a kaggle notebook for it here: https://www.kaggle.com/code/edkenthazledine/chicken-breed-predictor-98-accuracy
Would appreciate any feedback ![]()
2 Likes
Hello, thank you for creating this course. Here’s my attempt at creating my first classifier, which I created along with the first class. I attempt to segregate Star Trek original and next gen characters.
https://www.kaggle.com/code/archanamaurya89/is-it-a-bird-creating-a-model-from-your-own-data/edit
Of course, it needs more work(and editing!) but do let me know your opinion, meanwhile. Thanks! ![]()
1 Like
Hey, that’s good work!
1 Like
It’s great ![]()
1 Like
Hey, Thanks ![]()
Hi Archana,
I am not able to open your kaggle link. Showing 404 error.
I see. Looks like it was private by default. I just made it public
Yes, i can see it now. Great… Keep it up great work ![]()
I made a model based on Lesson 1 that differentiates between Nick Wilde and Judy Hopps from Zootopia.
Hey there!
To understand the APIs of FastAI better, I took the multiclass classification problem; in this case I tried to classify the clouds in one of the 10 categories viz. Altocumulus, Altostratus, Cirroculumulus, Cirrostratus, Cirrus, Cumulonimbus, Cumulus, Nimbostratus, Stratocumulus, Stratus.
It was a fun exercise as not only I learned about clouds but also a few practicalities of model training.
- After initial training, look at the results and try to find the reason behind misclassification. It could be due to poor data, fewer data points or other glaring issue. I removed one of the very lossy class from the data. It was the class of the cloud that keeps shifting its shape and altitude and ends up resembling many other classes.
- Use the learning rate finder, it is your friend.
- Keep calling garbage collector or emptying the cache of the Torch to avoid running into CUDA memory issues. (Sooner or later this error comes up, I need to learn more about the memory management).
- Training for one epoch and then training again for a larger number had somehow a positive impact on the results. It’s like warming up the GPU(not sure though)
- Using discriminative learning rates and epochs as training progressed was rewarding. It provided a lot of stability in validation loss and accuracy.
- Reading the source code helps.
I wrote the notebook and eventually turned it into a blog post here - What do you see when you look up? | Musings of Learning Machine Learning
The same is present on Kaggle, in case anyone wants to replicate the work and make improvements.
Thanks!
3 Likes
For people working currently through the NLP lecture (as I do ![]() ) the following blog post I wrote might be interesting. I try to tackle the current NLP competition on kaggle.
) the following blog post I wrote might be interesting. I try to tackle the current NLP competition on kaggle.
It’s my first blog post in general and I did it with fastpages.
I would be very happy to get feedback ![]()
P.S. The notebook can be found also on kaggle
3 Likes
I was able to score my first submission on the NLP challenge. See my new blog post or the corresponding kaggle notebook for more infos on how I did it.
Until now everything is pretty basic but at least I’m officially ranked in the leaderboard now ![]()
2 Likes
New blogpost containing a much better readable training and inference section.
They can be found also on kaggle:
1 Like
Hi all, excited to share my first project Moth or Not? (copied and edited from the “Is it a bird?” notebook)
Requesting all to genuinely post their feedback in the form of comments on:
- How to improve the model’s probability
- Making sense of …
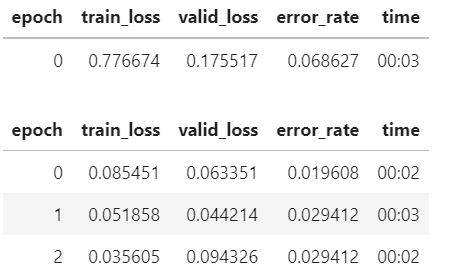
- Other things to consider
1 Like
Hi everyone, I started this amazing course last January and since then did the following:
-
Brand detector to identify potential patent violations between Adidas, Nike and Puma
-
Wildlife classification using real imaginery of jungle cameras
-
Amazon clearance track to see changes in landscape and forest cutting
-
Crowd counting to help public transport planners to estimate people using trains
-
Whale id detection based on top views using siamese networks
-
Pump failure prediction using tabular learner and categorical embeddings
-
Poetry creation using LSTMS and ULMFit approach to get realistic poetry
In all of the projects I reach either top 10% leaderboard positions or barely 1-2 pp accuracy difference with respect the state of the art, working on each project around 8-10 hours maximum. I find this course and the library amazing, thanks for helping my career and development so much, it is a lot of fun. My work can be found in my Blog or Repo
4 Likes
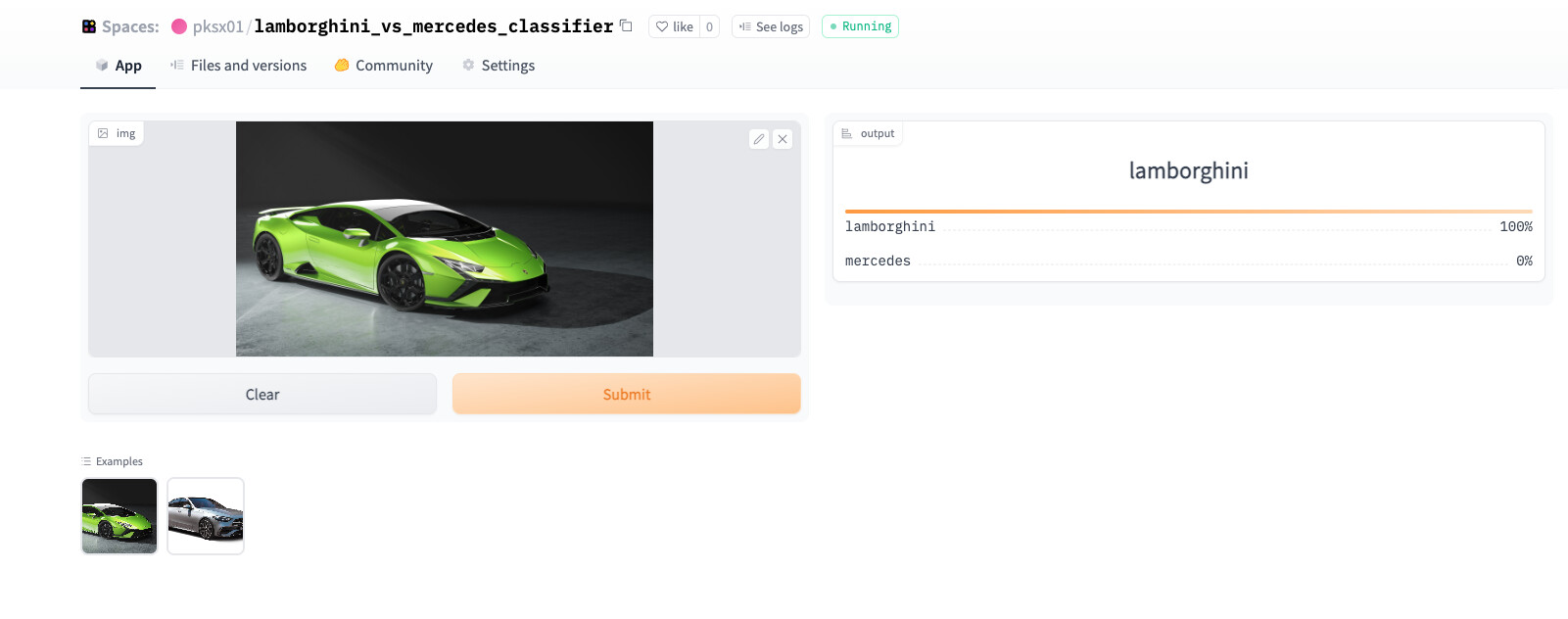
Created a classifier which classifies an image of car into Lamborghini or Mercedes Benz using the concepts taught in Lesson 1 and deployed them on Hugging Face Space after creating Gradio app.
I watched the pre-recorded video of the first lecture last week and I am really excited to have found this course. Following the steps outlined in Lesson 1, I tried to use the model to recognize a man and woman where the accuracy was close to 1. I also try to train the model with only subtle differences between pictures which could be hard to distinguish for the naked eye in some cases ( faces with makeup or without makeup). In the latter case, the model didn’t perform well. My assumption is that we may have to train the model with a larger sample or increase the no of epochs. My hope is that I will have enough knowledge after this course to figure out what I need to do to increase model accuracy.
After finishing lecture 6 of the course, I took at stab at my first kaggle competition and decided to recreate the lesson, but with the spaceship titanic dataset/competition. Check out my notebook here or my blog here, still working on some finishing touches but managed to get into the top 50%. Let me know what you think and how you would attempt to improve the model! Thanks
Congrats on the great progress! If you could tweet about these projects and put a link here, I can retweet it for you.
1 Like