I’m thinking of the same problem as you. In my case, it’s fruits classification. I want to add another category: Not fruit/Unknown. I will probably try it in the weekend when I have more time, I don’t know how it will go.
1 Like
Hi, Satish:
I think the problem you have is this: you didn’t specify another category that’s specifically reserved for “NON-RICE”. As a result, the prediction will ALWAYS be one of the categories that receive the highest predicted probability.
3 Likes
One more (final!) update regarding the Kaggle competition where I participated during the course. I managed to stay in the bronze zone on the private leaderboard and become a Kaggle expert. It was a great and actually a quite joyful experience. I did participate in competitions before, but it wasn’t always that nice because I used to put lots of efforts into debugging and coding, and less into data modeling.
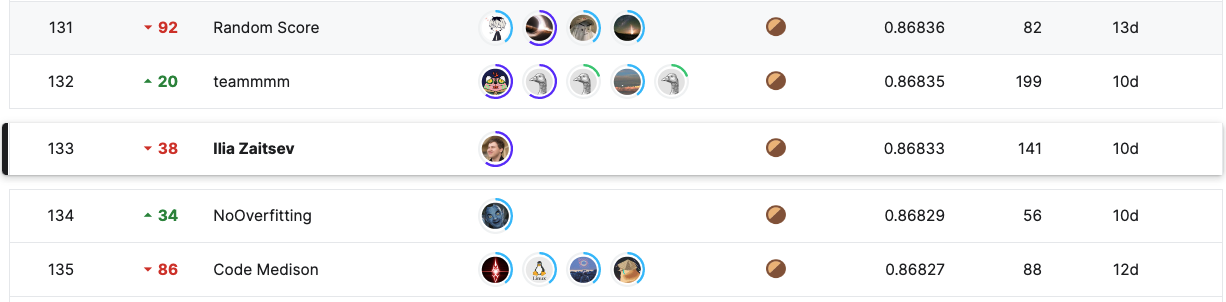
I created a notebook showing a basic version of the solution that helped me to achieve that. It’s rather “boring” by modern standards, as it “just” trains an EffNet backbone with U-net decoder and applies a bit of data augmentation. (The key was to use an ensemble of many models trained on different subsets of data.) Also, as you can see from the screenshot above, I’ve somewhat overfitted the public test. Still, I think this solution may be useful for someone who wants to apply fastai to image segmentation tasks.
The notebook covers such questions like:
- How to deal with the data that has more than three channels
- How to prepare data block and third-party augmentations
- How to write a custom data loader that oversamples positive examples
- How to evaluate the quality of a trained model
- How to load trained models and do the inference with them
Looking forward to the second part of the course!
21 Likes
Brilliant stuff ! Congrats on the bronze. ![]()
3 Likes
I ran out of time for my Malware research. Here is a presentation I did for my local DEFCON group. As I go back and readdress the different methods used to compare them I will update it.
I tried to use RISE to present. I have to say I was not a huge fan of it.
1 Like
What issues did you have?
I wrote a blog post explaining the code of the DuckDuckGo Image Scraper from Lesson 1.
1 Like
if decode is set to True, the response is decoded. The default is True as information is generally communicated in encrypted form, so we definetely want to decode it into a readable string.
Be careful not to just guess what things are doing, but look up their docs and test them! decode() has nothing to do with encryption!
5 Likes
Thankyou ![]()
I have corrected the error.
Hi, I have a little problem with my image classification.
I am working on classifying coffee drink spills, water spills, and oil spills. The model I obtained however is doing a poor job with the validation test set, no matter the number of times I fine-tune the data
This is the link to the Kaggle notebook:
https://www.kaggle.com/code/davidakingbeni/is-it-a-bird-creating-a-model-from-your-own-data
During training, it also gives me a UserwarningError: > Palette images with Transparency expressed in bytes should be converted to RGBA images
“Palette images with Transparency expressed in bytes should be”
1 Like
Hello everyone!
After lesson 1, I played with the Kaggle notebook and made a classifier between hedgehogs (they’re so cute!) and non-hedgehogs (lions and hamsters, not sure why… don’t ask). After a few modifications, it worked! Here’s the result:
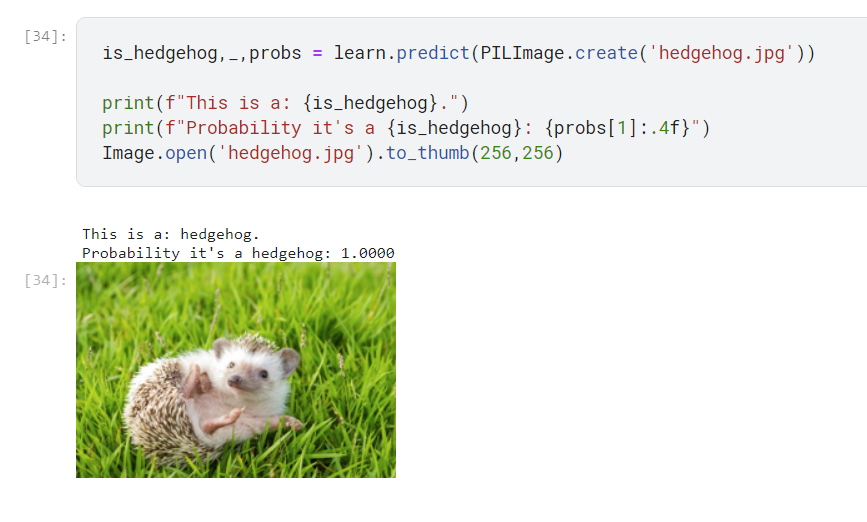
Here’s the link to the notebook: https://www.kaggle.com/code/mariesallaberry/is-it-a-hedgehog/notebook
I’m going to start lesson 2, make another model and push it to production! How exciting!
4 Likes
Wow yeah that is cute…
3 Likes
A hundred percent cute hedgehog ![]()
1 Like
I get a “404 Can’t find that page” error with your Kaggle link. Is it public? To test try your link in another browser.
Thank you @bencoman, I think it is because of the modification I made to the file. Here is the new link and I already made it public and tested it with a friend, thank you: Spill classification | Kaggle
I copied your notebook and can confirm I see your error. I don’t have time to dig right now, heading out of town for the day. Could summarise what you learn from the first few of pages here to help me follow up when I’m back.
1 Like
Alright
I have gone through the first few suggestions and I think the problem has to do with the transparent level of my PNG files or the file formatting. The first code I tried was to check the number of images that were actually giving this transparent issue and viewed some of the images.
The next thing I did was to try to convert RGB files(Transparent files) to RGBA (Files with background) using one of the codes that were there (I had to adjust the conditions and comment out some lines).
It is already working and training now without the error and I see some great improvements on the valid_test already. Thank you.
1 Like
I think the biggest issue was struggling with my visuals and what was presented on each slide.
I ended up presenting every cell independently and resizing on the fly with the in-person presentation.
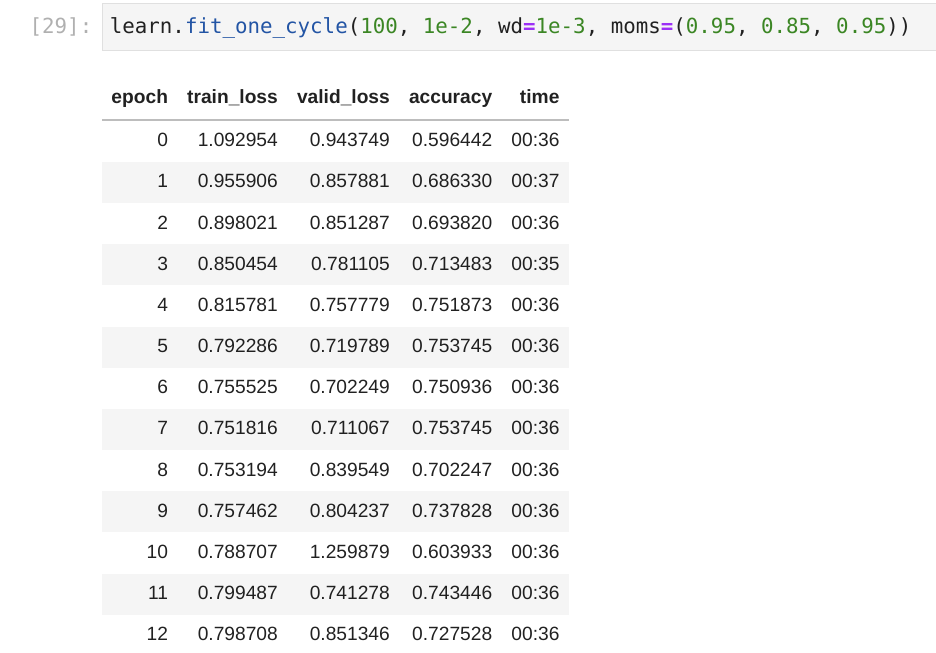
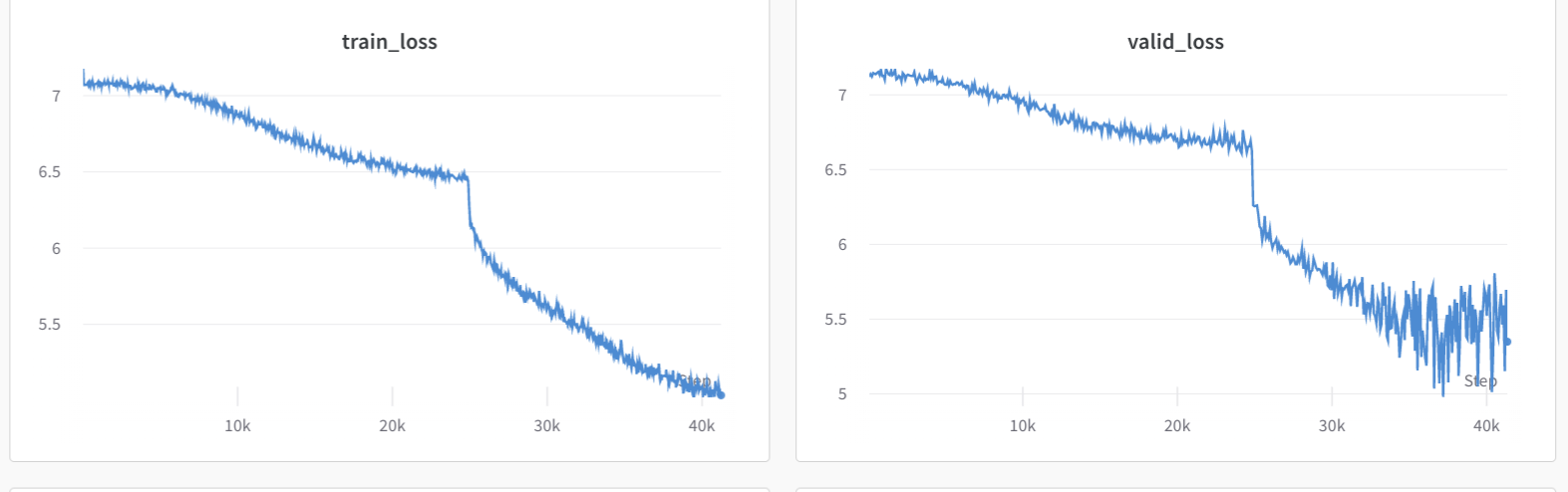
Early report: I’m working on a live challenge here on Zindi, and decided to try to use self-supervised pretraining for an advantage. Here’s my implementation, which I shared as it contributed a new pretrained encoder that had good generalization properties. I noted consistently lower validation loss than training loss, although the effect quickly disappears at low batch size like in this image, and is much more consistently visible at much higher batch sizes i.e. 256:
This is the nice loss curve when a unsupervised model converges:
7 Likes