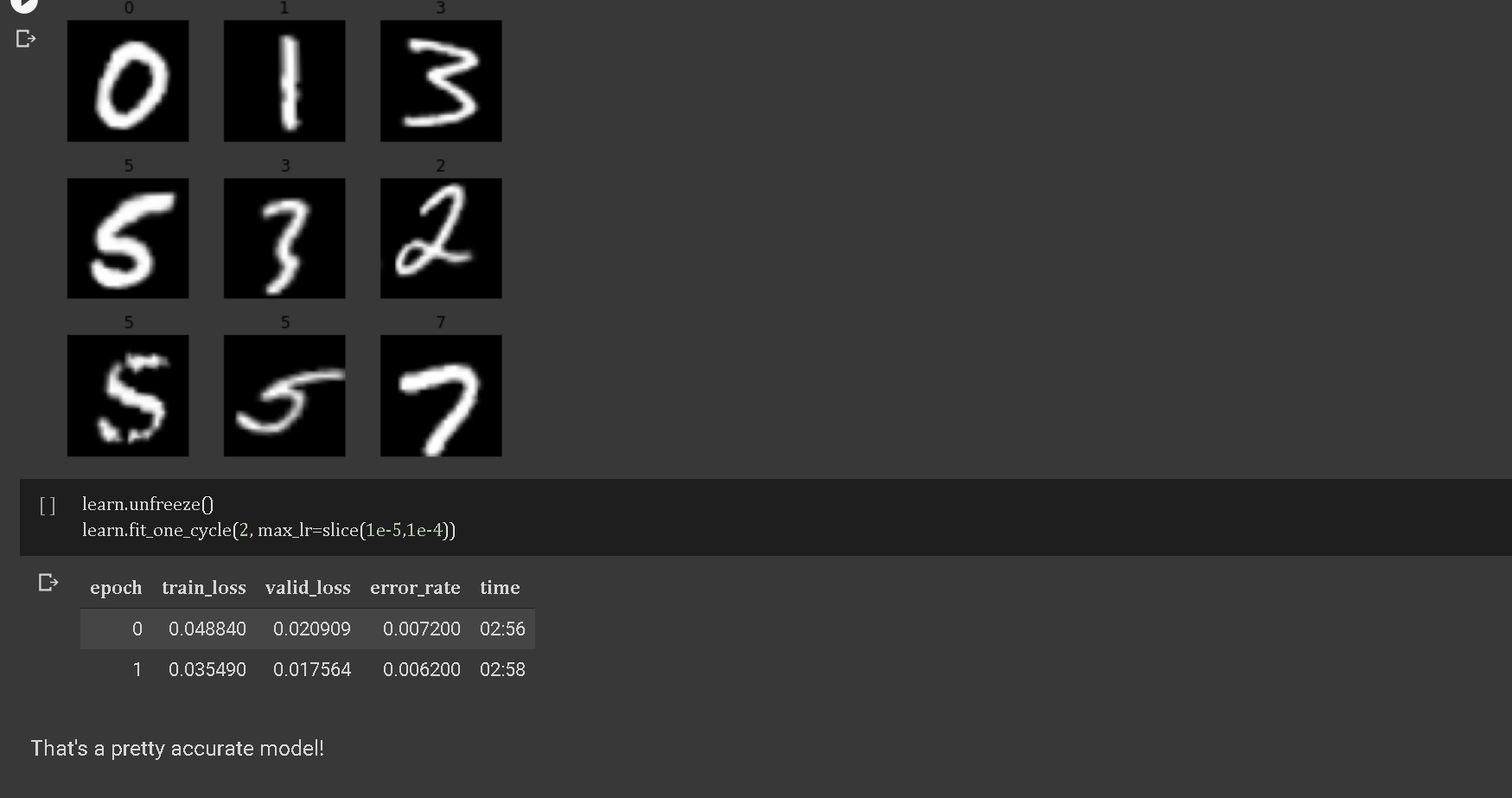
I just finished lesson 3, and I decided to create a mask classifier that checks whether an image contains a person without a mask, with an improper mask, or with a proper mask. Here are the results (It had a 93% accuracy rate)
As shown here, out of the 21 images, 2 were classified incorrectly. I was working on limited images, so I am quite pleased with the result. Working on this project really helped me understand what lr_find did and to a certain degree, how it worked using gradient descent.
Credit to Luca Martial (stochastic) for the datasets with masks proper and masks improper. GH for dataset
Credit to Dhruv Makwana for the dataset with no mask. Kaggle for dataset
I hope are doing all well. I am facing a problem with the datatype of the Satellite image which is float32 when I split it is all black and When I try to convert it to an unsigned 8 bit all turns white and my histogram explode. I would like for the mages ot to be black since I am using python for my work and it maximumly accept [0,…,255]. Plz I need help
joell, first you need to start a new topic for your problem. don’t post in the middle of a thread about something else or the forum gets completely disorganised very quickly.
secondly you need to include more information. code, links, error messages, what you’ve already tried etc. you haven’t given enough information for people to try and help you.
Hi everyone!
It’s my first week learning fastai. With absolute no knowledge about code I was able to train a model to classify MNIST handwritten digits with 99.38% accuracy. The current SOTA model has an accuracy of 99.97%. So… Thanks @jeremy, fastai, and this wonderful community.
Just wrote my newest blog examining fastai2’s test_dl method and how it can be customized if your inputs aren’t quite stored the same way as they were during testing:
Tried out image segmentation on the UNIMIB2016 Food Dataset, using Unets from fastai. Great public dataset from the folks at University of Milano-Bicocca, containing over 1,000 images of food trays.
Results were pretty good, reaching nearly 90% accuracy (after discounting the background pixels).
The Gibson Les Paul and Fender Telecaster are two iconic guitars which have very distinct shapes (and sounds). Gibson and Fender each have subsidiaries, Epiphone and Squier, which are authorized to create lower-priced Les Paul and Telecaster models. These budget guitars are very similar to the premium brands, with slight visible differences such as the headstock and logo. I expect a good classifier to distinguish between any Les Paul and Telecaster well, but to only distinguish between premium and budget brands when the information is available, i.e. a good view of the logo or headstock.
Training a model with the original dataset achieved an error rate of 41% after fine-tuning. The confusion matrix showed (left) that there were many errant classifications between corresponding premium and budget models. Using the image cleaner widget helped remove images where a human could not make the determination between premium and budget brands, such as a view of the body only. I inspected roughly one hundred images, pruning a third or so, but didn’t see any signs that the trend was improving. I also removed a few duplicates, but it seems that there weren’t many in the dataset. Training a model after partially cleaning the dataset showed modest improvement in both error rate 37% and confusion matrix (right). It appears that spending the time to clean the dataset will result in the largest model improvement. I originally used 300 examples for each class, with the idea I would have to remove many. However, I didn’t consider how much time that would take. It might be interesting to start with a smaller dataset, say 50 examples of each class, and prune the entire dataset. Overall, the model performs fairly well. There are some very accomplished guitar players who find it hard to tell the difference by feel or sound!
A couple of ideas and questions emerged from this exercise.
Could I train a model to identify images from the original dataset that show the full guitar, so that classification is possible?
What kind of work has been done on hierarchical classification, where the classifier might be able to say “I know it’s a Les Paul, but not sure if it’s a Gibson or an Epiphone”?
After developing the model, I learned of Christian Werner’s similar and more developed work on a guitar classification app called AxeNet. I’m looking forward to trying it out.
If you look at the third part of the tuple returned from learn.predict() it’s the probabilities of all the classes, so it might be 0.873 likely it’s a Gibson, 0.361 for epiphone and something very very small for the teles.
Thanks, good idea. Here’s an example of an Epiphone Les Paul image.
Looking at outputs = tensor([0.4910, 0.0021, 0.4018, 0.1051]) corresponding to learn.data.classes = ['epiphone_les_paul', 'fender_telecaster', 'gibson_les_paul', 'squier_telecaster'] shows the highest probability of 0.4910 corresponding to correct Epi LP classification. The probability it is an LP of either variety is 0.4910 + 0.4018 = 0.8928. Note that the softmax function at the output of a multi-class classifier normalizes the sum of all probabilities to one, as is the case here, so the hypothetical probabilities 0.873 and 0.361 you provided should not arise in practice.
I’ve been blogging since your choices were “write your own blog system”, “host your own wordpress installation” or “blogger”, and I don’t think I’ve been this happy with anything for a long time.
blogging with notebooks is so absurdly good it’s amazing nobody thought of it sooner. I can’t wait to see what ridiculous thing Jeremy thinks of doing with notebooks next.
Amazing work! Thats impressive, especially considering how similar epiphone and Gibson Les Paul’s look, and (even fender and squier telecasters). It might be a result of data bias, but assuming its not, your model has learnt to differentiate the finishing of the body, the shine, and even relative contrast in wood colour. Thats mind blowing, don’t you think?
I trained a model that takes a picture of a road accident, and tells us if its a car crash or a bike crash. The accuracy is about 93% with a resnet-34 model, before any data cleaning.
Most of the misclassified images had both, a car and a bike, involved in a crash.
After some data-cleaning (removing duplicate images, deleting unrelated images), I was able to improve the model performance to about 95%., where I used various learning rates to see what works best.
Hi guys!
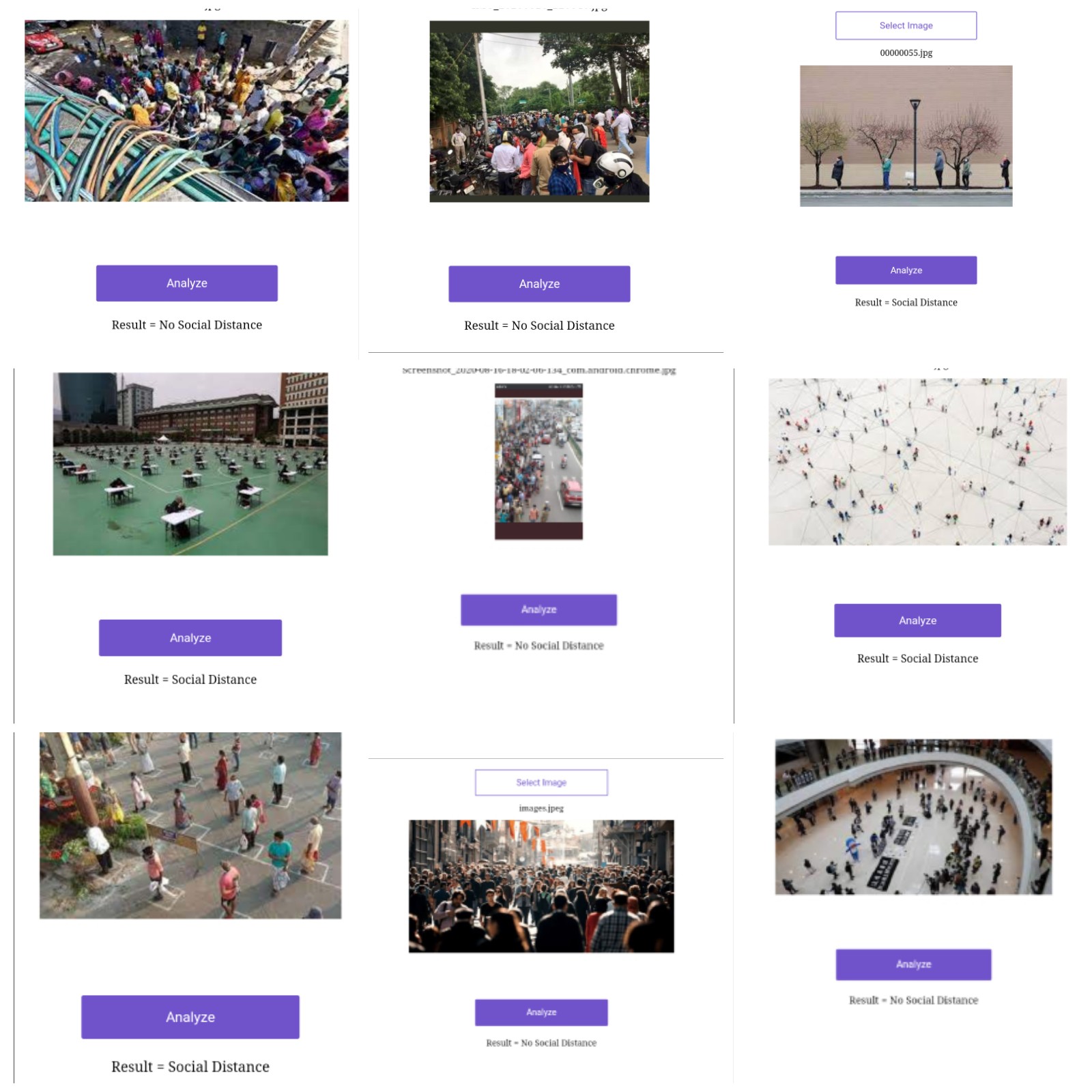
I am on lesson 2 and was wondering if I could use what I learnt on some ongoing problems. That is when I stumbled upon the idea of using a neural network to check if social distancing is being followed in a place or not…
There was no publicly available dataset so I scrapped Google for images on both the categories. Although I found a lot of images it was all mixed up. Apparently Google’s algorithm was not able to classify them correctly.
So I manually separated the images and trained a model. To my astonishment it was able to classify with 86% accuracy!
I think it can be used in CCTV or drones for surveillance of public places. It will certainly help law enforcement in these harsh pandemic.
You can check it out here: https://mlvscovid.herokuapp.com/
If anyone is interested to collaborate please do, I have just started the project.
Special thanks to @joedockrill & @sachin93 for helping me setup the webapp(believe me or not it takes a lot more time and patience than training the network, if you are a beginner like me😅)
@mmd Amazing work! Glad to hear that I could be of help. I am a beginner myself and I understand your pain since I come from a Civil Engineering background with little programming experience.
 ?
?