I want to share my work as an example of Jeremy’s words on how we can achieve great results without a ton of data and computations. I used a pneumonia dataset (http://www.cell.com/cell/fulltext/S0092-8674(18)30154-5) and compare fastai v1 results with original paper.
To not bother you with much citation, authors achieved accuracy of 92.8%. But I should mention, that they train Inception v3 network pretrained on the ImageNet for 100 epochs with a batch size = 1000 images, which is really huge.
The key takeaway here is we can get really great results from deep learning with not so much data and computational power. Thanks to fast.ai and great community for sharing knowledge))
So I wanted to compare my “old ways” to the “new ways” which Jeremy made use of in Lesson 1, e.g. the ResNets, 1cycle scheduling, and fine-tuning/freezing/unfreezing. Also I wanted to become familiar with using fastai on Google Colab.
The “new ways” of Lesson 1 yield about 92% accuracy and my old ways produce about 91% accuracy.
Unfortunately the actual demonstration of my Keras model within the same notebook fails, apparently because of conflicting versions of CUDA between the new PyTorch and the CUDA which Keras/Tensorflow expects to see. So you just have to take my word for it right now, until I can get around that.
The lack of huge improvement in the score could be because
the particular audio dataset I’m using this time is fairly ‘noisy’, or
my old ‘simple’ model actually does tend to work pretty well (as I’ve used it on other datasets), and converges pretty fast.
It could be that the ResNet+1cycle method reaches the same accuracy in fewer epochs, although a comparison of wall time would also be worthwhile. Work in progress! I may just have to create a separate notebook to demonstrate the Keras model. (Alternatively, I could rewrite the Keras CNN itself in PyTorch…someday.)
On the Bangla Lekha-Isolated dataset for Bengali character recognition (84 class classification), I able to get the error rates ~5.3%. This is a 84 class classification. The error rates can still improve if I keep training a few more epochs. I have used the dataset available at https://data.mendeley.com/datasets/hf6sf8zrkc/2
First version of results:
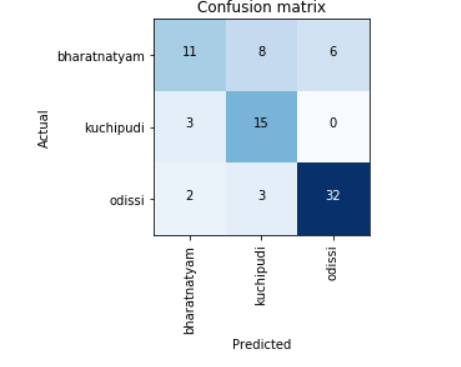
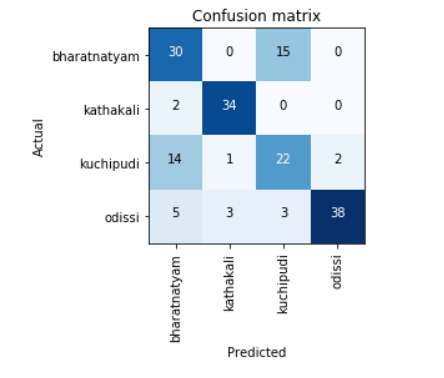
After lesson 2 I realized that size of dataset needs to be increased. Also, to check how the classifier is performing I added a 4th class, which is expected to be very easy to differentiate for humans (this dance form specially uses face paint).
This time I found the results to be much better:
Will be interesting to see what part of the images got activated for the various dance forms. If it is eyes for one dance form and hand shapes for other dance forms, it will all be such wow
I think Jeremy will come to that part in a later lecture. I don’t exactly remember but this was a part of last years lecture 7. Go to this notebook https://github.com/fastai/fastai/blob/master/courses/dl1/lesson7-CAM.ipynb and have a look. It will help you highlight the places which activated a certain class
Thanks for sharing @ademyanchuk! It’s certainly amazing how powerful DL is, even when applied to a dataset different to images in ImageNet.
Is this a publically available dataset? I’d like to experiment with it a bit if it is.
Was inspired by the lesson 2 image download, I re-adapted the code to use it to download high quality images from EyeEm (which is used by pro photographers).
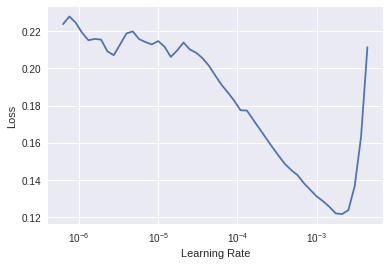
I got a nice curve for the learning rate
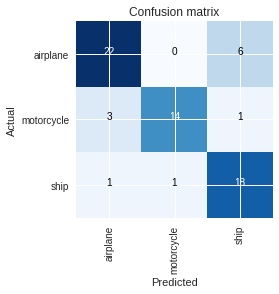
And some good results when looking at the confusion matrix:
Here is a blog post summarizing the steps for creating a dataset of images using this service - link.
Here is the complete jupyter notebook - link.
Tried to build a web app for serving an emotion classifier using same service used to win science hack day mentioned in lesson 2. The classifier didn’t had great results, but nevertheless was able to see that Samuel Jackson is angry:
> Upload [====================] 100% 0.0s (83.34MB) [3 files]> Error! Upload failed
> Error! An unexpected error occurred!
Error: File size limit exceeded (5 MB) (400)
at responseError (/snapshot/repo/dist/now.js:2700:15)
at <anonymous>
at process._tickCallback (internal/process/next_tick.js:188:7) Error: File size limit exceeded (5 MB) (400)
at responseError (/snapshot/repo/dist/now.js:2700:15)
at <anonymous>
at process._tickCallback (internal/process/next_tick.js:188:7)
It seems need to upgrade paid. I think Bardem next movie should be no country for poor men
Any way, I think the world can wait few more days until I find a free service
I automatically downloaded 99 images for three kinds op medical packaging. Paracetamol 125MG, 500MG and 1000MG. Resulting pictures are of good quality, below some examples:
I expected it to learn quite fast because imagenet is capable of segmenting/filtering text inside an image. So I would expect it learned to associate the numbers in the image with the corresponding class.
But even training with Resnet50 it is wrong on 1 out of 4 images, while the images are correctly classified, eg:
Probably the model sees other patterns. Any suggestions for debugging or improving? Of course more data would improve the model.
Can I somehow/force hint the model it should look for text? I’m thinking of generating some data myself with only text in different fonts/colours/sizes/angles.
I’ve made story about classifying fruits dataset with fastai. I am aware that the code display method should be consistent (some is written in markdown, some is screenshotted), but I got lazy tbh.
 So you just have to take my word for it right now, until I can get around that.
So you just have to take my word for it right now, until I can get around that.