Hi Everyone!
A little more on my satellite project. (a lot actually  )
)
First - you can try it in a nice-ish webapp: yourcityfrom.space
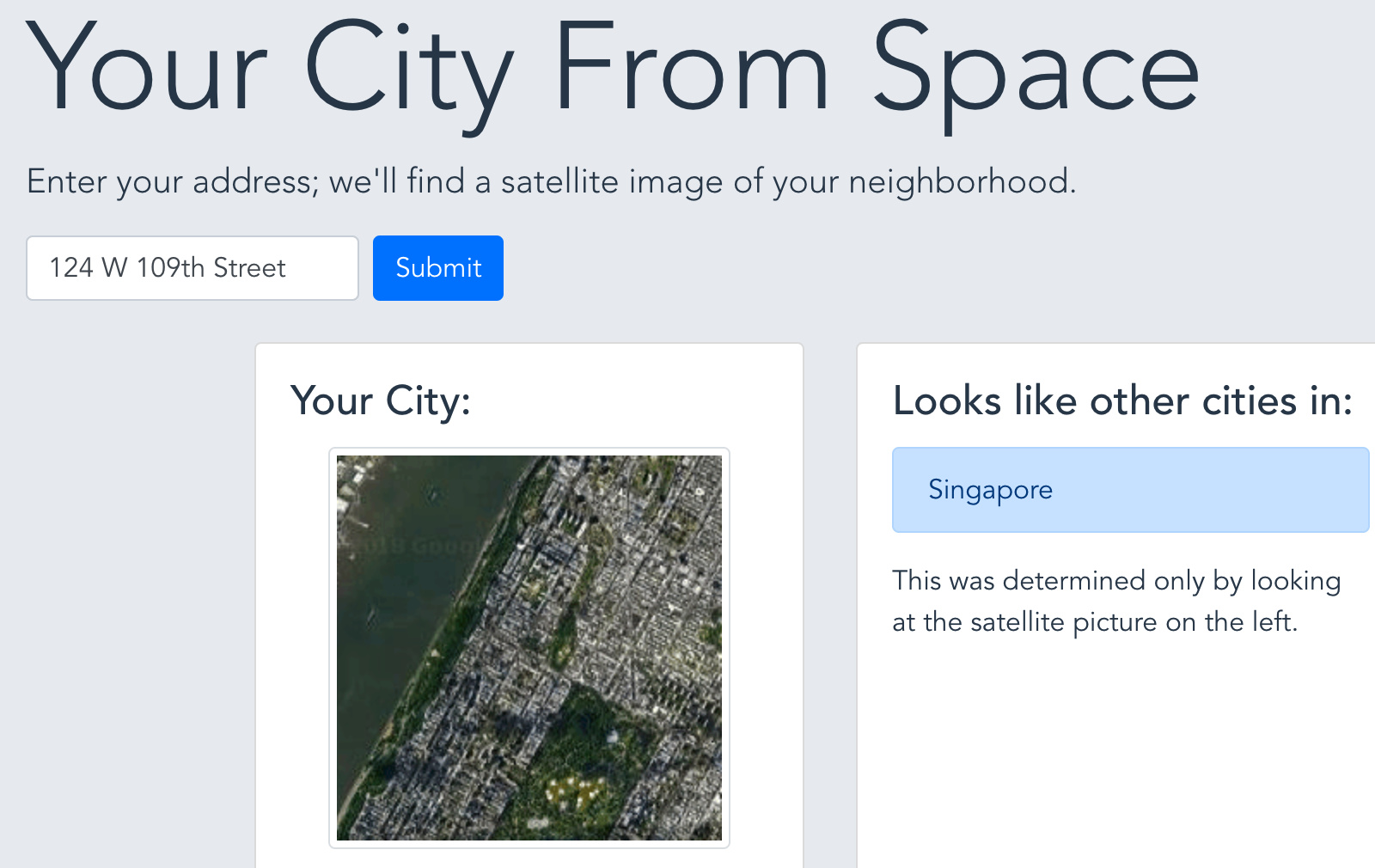
I’ve played around with a couple production and serving pipelines and ended up serving everything the old-fashioned way from a digital ocean droplet. The code and a little more about the backend and frontend are in the github repo
More interesting is the fact that when confronted with examples outside the initial dataset (which was split in training/test), the perceived accuracy is much less than the 85% accuracy on the validation set.
I think that’s very representative of trying to use DL in the real world, where you collect data, split train/val, and then get so-so results when model is in production.
Anyways, I spent a bit of time trying to figure out what was going on. It comes from the data collection methodology. To make a long story short, the 4000 images in the original dataset were sometimes “too similar”; essentially patches that were next to each other geographically ended up getting split into train and validation set, which boosted the validation accuracy significantly, but didn’t generalize to images collected using a different method.
I thought that was a super interesting teaching and am looking forward to seeing if I can fix this by improving my data collection methodology! Will keep you posted.