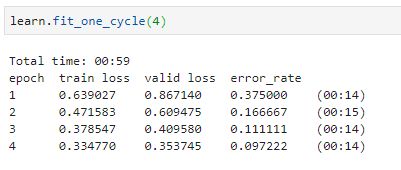
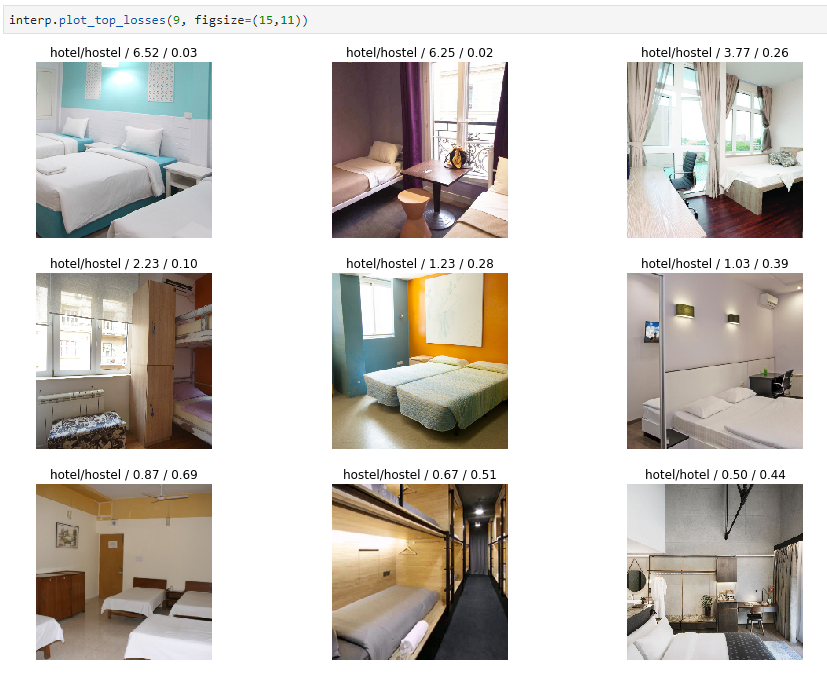
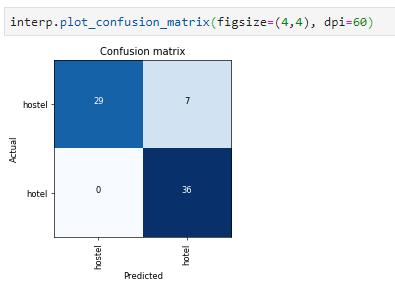
I used same lesson-1 template with Resnet34 to classify hostel and hotel rooms. Dataset is created with by using Google Images Download and some images are removed manually to increase quality (final: 240x2 images). Accuracy is ~90.3%.
Some issues:
- Chromedriver have to be download to scrape more than 100 photos with Google Images Download.
- Some photos are bigger than limit. This causes to see “IOError: image file is truncated (nn bytes not processed)” in data normalize step.
from PIL import ImageFile ImageFile.LOAD_TRUNCATED_IMAGES = True
Adding this code beforehand helps to continue to process with truncated image.
RESULT