Hi everyone, after lesson 2 I created my own image classifier to differentiate between 10 different medications: Allopurinol, Atenolol, Ciprofloxacin, Levothyroxine, Metformin, Olanzapine, Omeprazole, Oxybutynin, Prednisone, Rosuvastatin. The specific strength of each med is noted in the notebook
As a former pharmacist turned software developer, I thought it would be interesting to see how a ML model would perform.
I sourced images from US National Library of Medicine’s Pillbox and google images. As you can tell, google images included quite a bit of junk images.
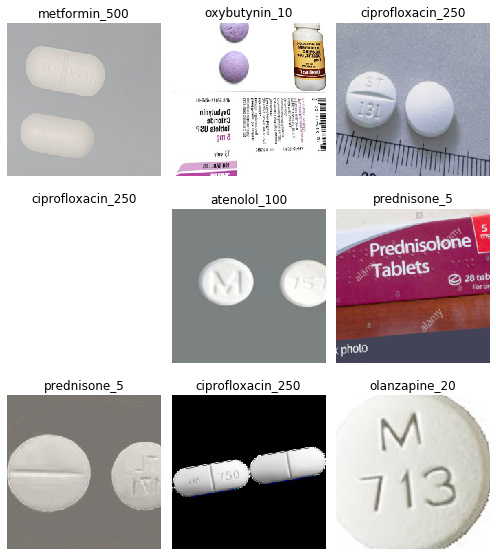
After cleaning up the data and experimenting with epochs and learning rates, I trained resnet34 on the final dataset.
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(5, max_lr=slice(1e-3,1e-2))
The model had an accuracy rate of 63%. Here’s the notebook on github
Steps for improvement include getting more images, and discarding more junk images.