I spent some time this past week building a dataset curator. It’s essentially two parts: scraper and curator.
The scraper grabs images from google image search based on your search phrase. It’s multithreaded and pulls down between 300-400 images per search in 30ish seconds on my laptop. It requires you install chromedriver somewhere on your file system and also the python package selenium.
The curator portion is an in notebook interactive session to locate duplicate/near duplicate images and garbage images in the downloaded data. It uses the intermediate layers of a pretrained vgg network and compares images based on the mean square error between their intermediate representations. If two images have similar representations then they’re probably very similar. It actually works really well! For garbage image detection, I look at those same intermediate representations and give images a score based on their total dissimilarity to all the other images in the set. The idea being that images that don’t belong will be most different from the actual “in class” images.
For both dup detection/garbage selection you’re presented with images in your notebook in order of their score (so most similar pairs will be shown first, etc) and asked to make a decision with a simple menu. The notebook cell clears its own outputs before presenting the next set of images so that your notebook doesn’t get too flooded.
For both processes since the images are shown in order, you will hopefully only have to go through a few pairs (for dup detection) or a few singles (for garbage removal) before you start seeing the kinds of images that you want. When this happens you can stop the process with the menu, and call purge to delete the marked bad files from your directory.
Here’s the code if you want to try it out (it’s not production quality so use at your own risk):
https://github.com/wfleshman/DatasetScraper
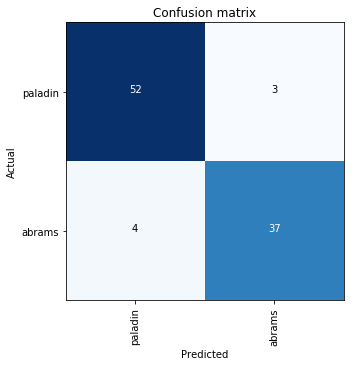
I used it to scrape images of Paladins (army howitzer) and Abrams (army tank) and built a classifier on that. I used to be an artillery officer and my family and friends would always mistake my Paladins for tanks. I was able to get around 94% accuracy by just training the new head of the conv learner on my curated dataset. So it looks like my family and friends should be ashamed of themselves