Hi,
I did an attempt to apply Lesson 1 and 2 to the RESISC45 ( RESISC45 (Northwestern Polytechnical University NWPU, Mar 2017) dataset and compare the results to the paper for the dataset - Remote Sensing Image Scene Classification: Benchmark and State of the Art (Cheng et al. 2017).
Link for the paper: https://arxiv.org/abs/1703.00121
The results table in the paper says that highest accuracy achieved at that time was 90.36% (there is a possibility that I have misread it and actual highest accuracy is greater).
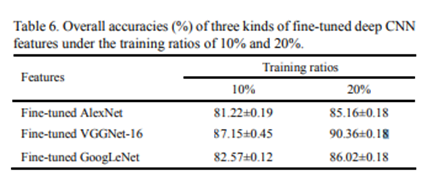
Attempted to apply ResNet 34 with bs of 64first, and the final error rate after unfreezing and retraining earlier layers was around 0.079 which suggests accuracy of 92.01% .
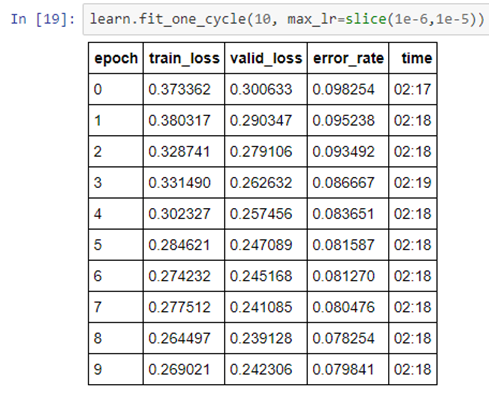
Then attempted to apply ResNet 50 with bs of 32 and got error rate of around 0.073 which suggests accuracy of 92.7% .
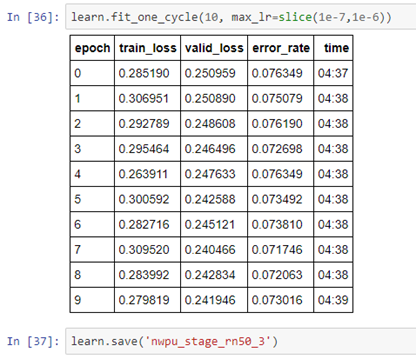
Cases that confused the model seem difficult enough.

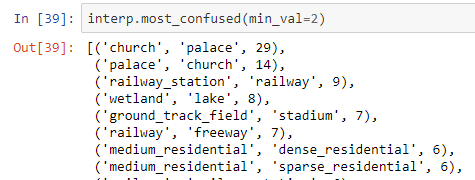
One curious thing was the fact that the number of times when some of the most confusing pairs “fooled” the model is greater for Resent 50 compared to Resnet 34. Was wondering if this is due to the smaller bs used in Resnet 50 or just Resnet 34 is more suitable for this kind of problem?
Resnet 34 most confused:
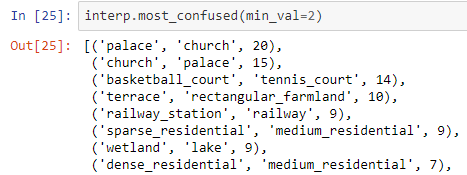
Resnet 50 most confused:
Was thinking to write something on Medium (a first for me), together with some more text related to the data and with sharing the notebook too (as soon as I figure out how to do this). Thought to share the above with people, open for any suggestions/opinions.