Hi!
Project Overview:
The project is about recognising shot-types/ shot-scale in cinematic images. The methodology is just disciplined application of Jeremy’s teachings. Nothing fancy there for fastai users. The fanciest part of the project is the dataset, which I spent a few months creating – this is where my domain knowledge as a film student came in handy.
There’s 8 different kinds of shots in cinema, and this project focuses on 6 of them:
- Extreme Wide Shot


- Long Shot


- Medium Shot


- Medium Close Up


- Close Up


- Extreme Close Up


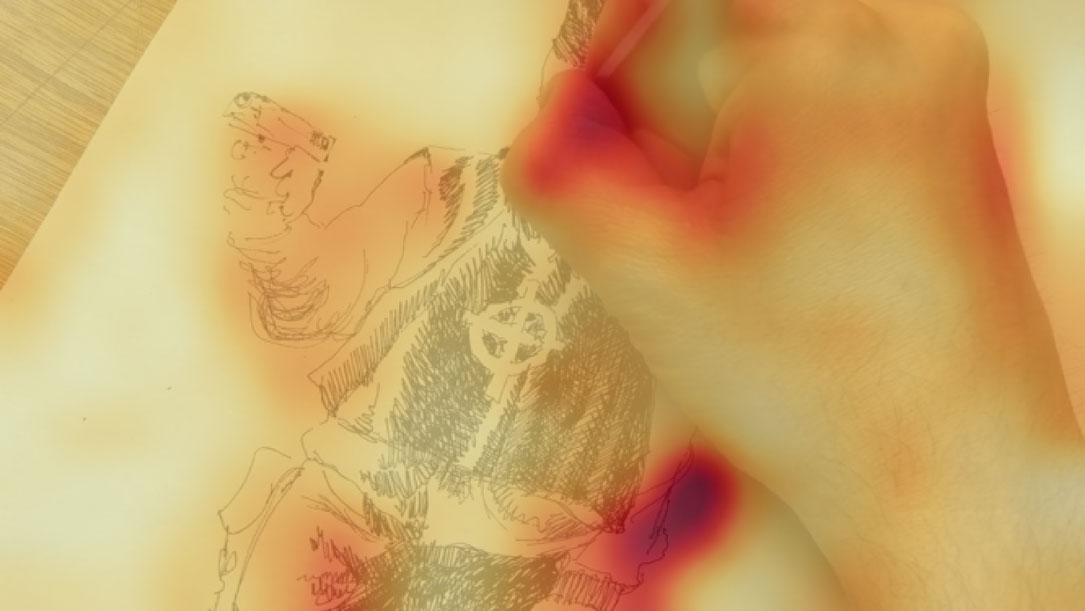
There’s also some fascinating heatmaps which really gives us insight into why the model works well:









Blog Post:
I created an interactive website explaining the project. The blog post is aimed at different target audiences – curious readers, filmmakers/ film students, and of course, deep learning practitioners like ourselves. It assumes no background in deep learning, filmmaking, or math.
I’d highly appreciate you taking the time to read this and give me feedback:
https://rsomani95.github.io/ai-film-1.html
GitHub Repo:
I also released the pretrained model, code and validation set in this repo:
I’ve kept the training set private because there’s more work to be done there. I plan on releasing it once I think it’s diverse and robust enough to train a great model.
I hope that this project kicks off data-driven research into film. I think there’s immense potential here to create tools that could be invaluable to filmmakers. Anyways, there’s more on that in the blog post.
Personal Background:
I’d been a Python programmer for 2 months before starting the fastai course, and it’s been an absolute pleasure to be part of this community and learning all this very accessible material.
I came into the course with no conceptions of what deep learning could and couldn’t do, but after watching just two lectures it was clear that I could solve a problem that I’d been pondering upon for about a year!
Thank you for your time, and thank you to the fastai team for making this possible. I’m extremely grateful for this course.