I was interested in doing voice recognition detection. I used Audacity (https://www.audacityteam.org) to trim the audio from the following clips:
- Ben Affleck’s speech in The Boiler Room (https://www.youtube.com/watch?v=JfIKzReNDF4&t=62s)
- Joe Rogan and Elon Musk Podcast (https://www.youtube.com/watch?v=Ra3fv8gl6NE)
And used 3 min 30 seconds of audio voice from each of Ben Affleck, Joe Rogan, and Elon Musk.
I used a 5 second sliding window to plot their spectrogram, using the tutorial outlined here: https://github.com/drammock/spectrogram-tutorial/blob/master/spectrogram.ipynb
Since there was roughly 200 seconds of audio, that gave me roughly 40 spectrogram pictures each of each person.
Here is a sample of the spectrograms for each class (I am not sure why some of them are warped - my original pictures that are uploaded are not warped):

Despite the warping of these pictures, I moved on anyways to see what will happen.
I trained it on Resnet34 over 4 epochs (default settings) and got roughly 60% error:

So I decided to go with Resnet50. The error rate improved to 30% over 10 epochs:
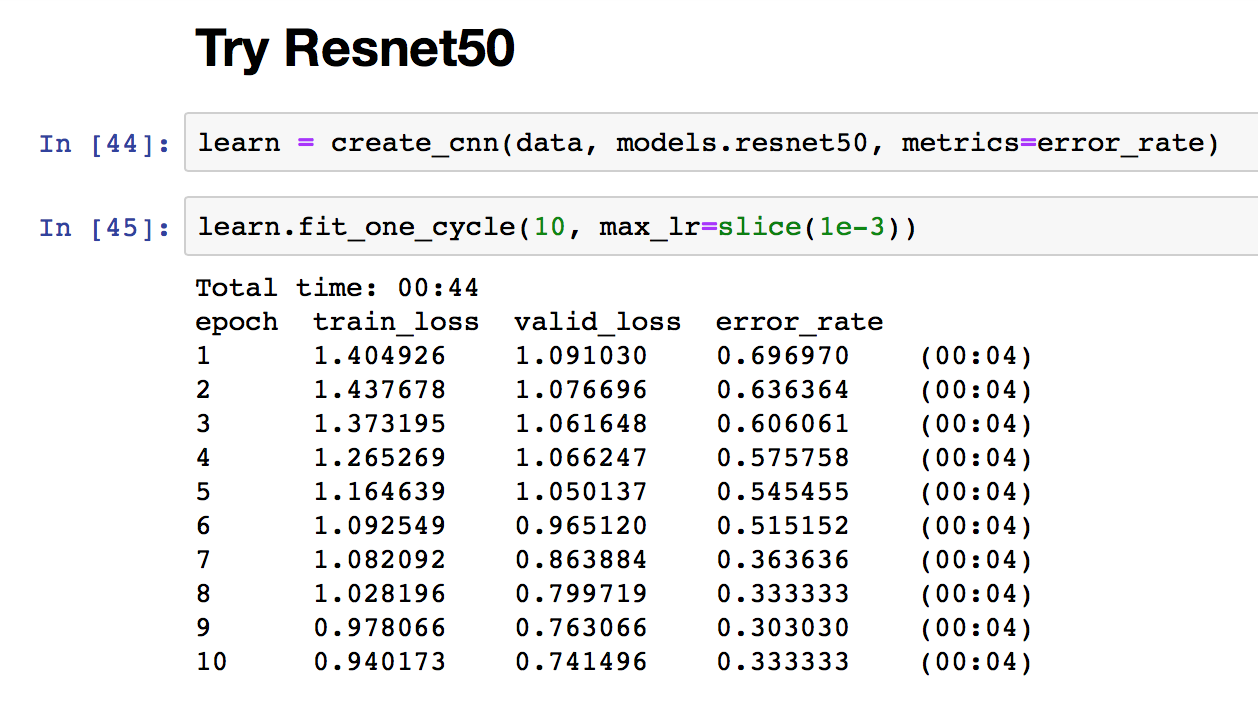
So, 30% is not quite as low as some of the other work that we’ve been seeing on here, but I’m quite pleased with the results:
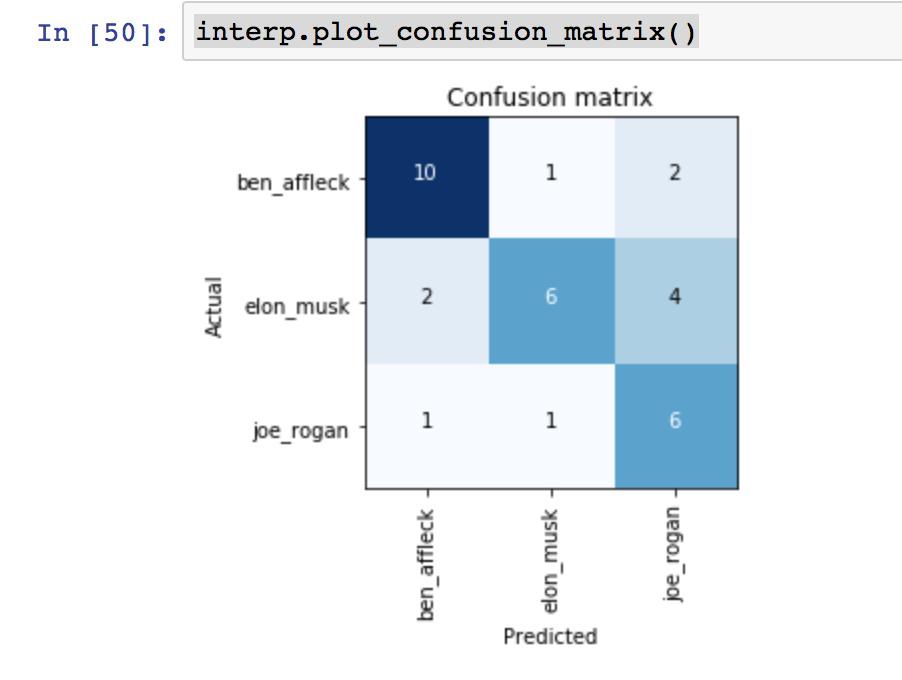
The model was pretty accurate with Ben Affleck and Elon Musk, while it was still better than random guessing for Joe Rogan.
I’d love to hear your thoughts on how I can improve the model. Obviously, I could add more training data - 40 samples each is probably too low (but this is a very tedious process to trim the audio to only a certain speaker and I might have run out of time for now). The warping picture issue is also concerning - not sure why that happened.
What do you think ? Otherwise, I’m pretty impressed that it did so well for Elon Musk and Ben Affleck for virtually zero tuning except to add epochs on Resnet50.
Because it did so well, I’m just convinced it will do much better on easier images  Those spectrograms look very similar to the human eye!
Those spectrograms look very similar to the human eye!
Thanks for reading this!