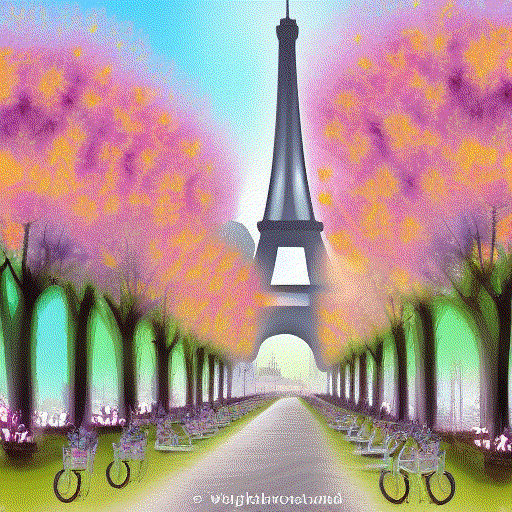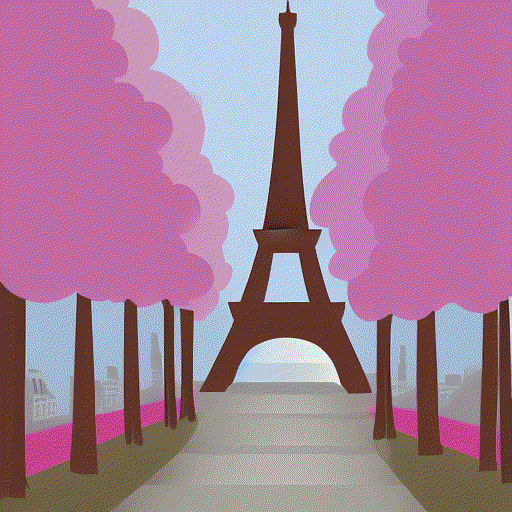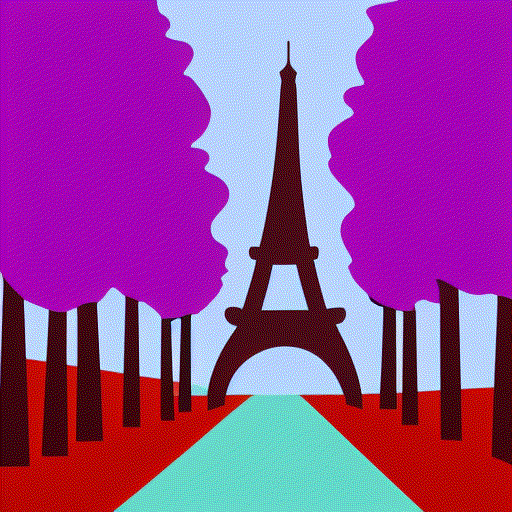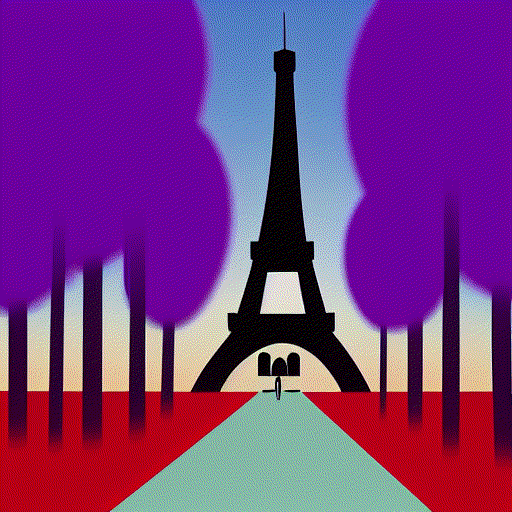Yes, I agree, that’s interesting how it works! I don’t know quite well how the tokenizer was trained, but it definitely can take at least some meaning from non-English languages as well. I also expected that one might encounter something like “unknown token” error, but I guess it is not the case for such large models. Was it trained on the whole Unicode char set?
That’s true! For some languages, it seems the model tries to generate the most common, “standard” image of that language/country. (Like showing cathedrals along the river for Russian.) Or falls back to some “generic”, even if not related, picture.
Thank you for feedback! I expected that for other languages it would produce even worse results. These complex models require some time to figure them out! I am still feeling a bit lost, even though I am familiar with independent parts of it. But definitely don’t know enough about the data.
That’s a good point. I was also expecting for images that aren’t quite aligned with the prompt for non-English languages. But it seems that somehow, for these two, the model indeed worked quite well! Especially, compared to others, looks very plausible.
Oh, you’re right, I’ve completely forgotten about the filter. I will try to disable it to get the results “as is.”
Yea it is fun using interpolation between multiple prompts. I generated the clip embeddings
for these 4 prompts
a = embed_text(['Paris in Spring, digital art'])
b = embed_text(['Paris in Summer, digital art'])
c = embed_text(['Paris in Fall, digital art'])
d = embed_text(['Paris in Winter, digital art'])
and then just did linear interpolation from a to b to c to d and grabbed some
clip embeddings along the way. Then passed each one into the model and made sure to use the same seed 23532 before generating each image so they would be similar enough.
UPDATE: I tried Jeremy’s suggestion below. I’m not sure I understood it correctly but I think the idea was to start with the previous image in the latent space (Image2Image) before going to each next step. So I used the ideas in the deep dive notebook on writing your own function for Img2Img. I played around with it for a while and tweaking the parameters and start steps. But things sort of get less detailed as it progresses. Still looks sort of neat but not sure what I was going for. Maybe there is a bug in the code
UPDATE 2:
I’m not so sure you actually want to interpolate the latent space by starting with the previous image as the input. I could be wrong but when I do this it leads to weird effects. I think you want to interpolate from a to b and to make it smoother (more stable) just add more points in between and set a consistent seed/noise. For example, I went back to the interpolation like I first tried without using the image2image suggestion. I simply added more interpolation points. See here. Do you think its better ?
Hehe yes that’s a nice simple idea. I think I had thought about that then got distracted and just wanted to finish something simple. I’ll give that a try tomorrow though
Not actually based on the lectures (I just started on the lectures and have only watched the first one) but I’m betting that the lectures will come in handy in revamping the image generation engine I use as I watch more lectures …
Here’s my GUI for Stable Diffusion which works on multiple platforms I’ve been using PyTorch/diffusers to handle the image generation part, but PyTorch/diffusers has become very slow on MPS/Apple Silicon lately. So I’m hoping that after the lectures I know enough to find a workaround for the slowdowns …
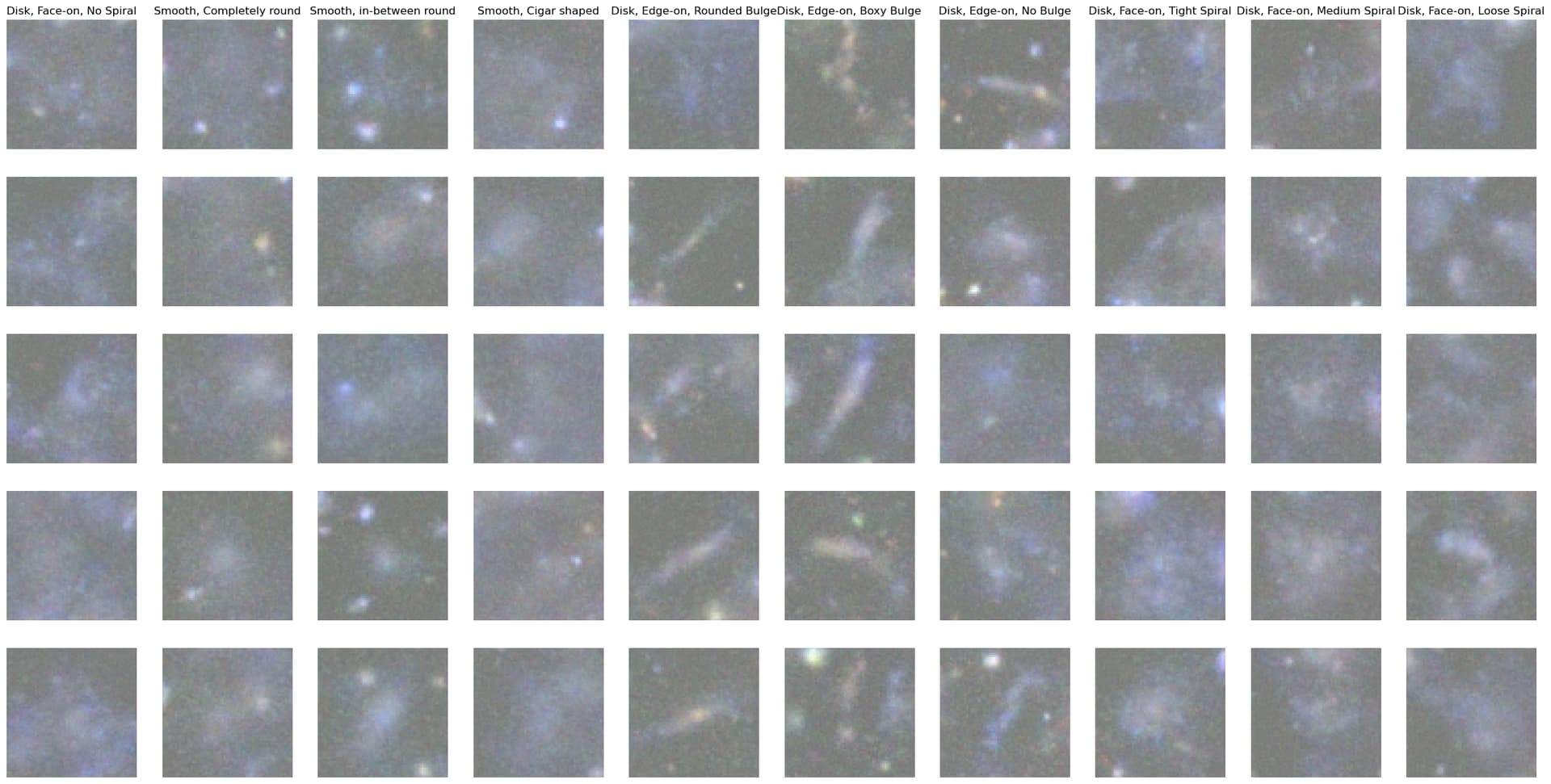
I’ve been trying to train a conditional diffusion model using a image dataset of galaxies that belong to ten different classes (Galaxy10-SDSS). I’ve been using an approach similar to @tcapelle’s code here which allows you to train a conditional DDPM by adding the label embeddings to the “timestep” embeddings. Notably, there’s no superresolution autoencoder or anything like that, but my images have shape (3, 64, 64) so they’re not that detailed.
Here are the middling results: everything looks very blurry and wispy. I’ve trained for 3000 epochs on this data set of ~20k images, but the loss seems to have plateaued for now. I’ve tested both MSE, L1, and a combination (Huber) loss function, but neither seems to mitigate this issue. Just curious if anyone has thoughts or suggestions?
I tried putting my Mom’s artwork into the Clip Interrogator to see if the output could be useful to her as an artist. Awesomely enough, it identified an artist she wants to study due to similarities in here style! She is quite excited after seeing the results of the first painting! I think there’s opportunities to create tools for artists I am going to play around with
Jeremy asked us to try to implement tricks like negative prompt in code. This gave me the idea of looking into the source code of diffusers library and write about it. Usually I don’t do these types of acrobatics . But this time I was confident enough to do so(many thanks to the lessons from Jeremy, Jono, Tanishq, Wasim and such a helpful community).
Here is me trying to explain stable diffusion and the source code for the famous StableDiffusionPipeline in diffusers library:
I also got blurry results in my font’s experiments the grey background should be white…
How are you normalising your input data? This has quite powerful effect, and your data should be in the -1,1 interval. Try this code instead of fastai. Also, are you logging your training runs somewhere? I would like to look at the metrics and intermediate samplings.
this course is as usual absolutely fabulous in every way Ive just published in TowardsDataScience an extensive article about generative AI from many different angles and Ive also mentioned fast.ai with a link to the web as the example that represents great organizations educating the world about generative AI, here is the free access link:
The article has also been included in Towards Data Science’s “Editors pick” and “Deep dives” sections:
Here is a little video created by interpolating between these prompts…
tree_prompts = [
“An oak tree with bare branches in the winter snowing blizzard bleak”,
“A barren oak tree with no leaves and grass on the ground”,
“An oak tree in the spring with bright green leaves”,
“An oak tree in the summer with dark green leaves with a squirrel on the trunk”,
“An oak tree in the fall with colorful leaves on the ground”,
“An barren oak tree with no leaves in the fall leaves on the ground long shadows”,
“An oak tree with bare branches in the winter snowing blizzard bleak”
]
I updated the input latents on every frame using the previously generated frame which overall improved stability.
I just implemented negative prompt using Jeremy’s function and reading Hugging face pipe code on negative prompt implementation , here are some results -
That’s an awesome use case! Have you considered turning it into a project/notebook and putting it up on GitHub or something so that other artists could do the same? I’m sure there’d be interest from other artists too …
That looks really great! I wanted to do something like this with cross attention control, but I like your version much better … especially the transitioning from one state to another. Really cool