Thanks, I’m happy to hear that  .
.
wow! cool project
1 Like
Very cool project.
I was wondering if you could post the distribution of your training data in the sense of the species. The reason why I’m curious is that I’m getting a lot of hits for Jacks that are actually yellowfin tuna and I’m wondering if things have been skewed. We worked on a project with pelagic fish and the problem was that more than 70% of our data was of albacore tuna so it seemed like when the model was to guess, it guessed albacore as that was the most probable to get correct. But there were yellowfin and bigeye tunas, Ono (or Spanish mackerel), sharks, sickle pomfret, Opah or moonfish, and a few others.
We had a difficult time getting around this.
I put a bunch of pictures that I have from the fishing we do here on Oahu with images of mostly yellowfin tuna (ahi) and mackerel (ono). As mentioned, lots of the ahi was guessed as Jacks.
Also, where did you get your images from? In the past when we were pulling images from google image searches such as ‘yellowfin’ we found a lot were mislabeled.
Thanks for sharing your model.
I`m glad to read that you liked the project, thanks for your comments!.
The truth is that the dataset is unbalanced and probably mislabeled too, it has many categories and while I’ve been careful to be consistent in the labeling while downloading the images, I’ve not been completely rigorous. This has been a project to do in my spare time, and I did it because I am in love with the sea and just for fun and learn.
I’ve obtained the images in various ways and from various sources (I do not share them because of copyright issues). I’ve tried at various times automatic downloads by scraping from google mainly, but those codes no longer work for me. First of all, I took fish classification list from the internet, I think from wikipedia, I don’t remember right now where I took it from, then I made a code to do web scraping from that list. The vast majority of the data came from these downloads. I have also searched in the browser cache, for example I search for a specific tag, load the images in the browser and then copy them from the cache to another folder and then the browser doesn’t block the IP address :).
Now I prefer to download them manually, even if it seems silly and counterintuitive, but I have more control of what I do. Because, the scraped images contain a lot of garbage, for example, the search engines bring a lot of drawings, cooked fish, mislabeled fish, or extreme things like what happened to me downloading triggerfish images, many of the downloaded images were of gun parts, and the cleaning process has been quite tedious and unfinished.
There is one important thing, and that is that I am not a marine biologist, so I could have made many unintentional mistakes in the way I have grouped the species, this could also influence, I think, in the labeling errors.
As you, I’ve also encountered problems with some of my own dive images, and the classification is not the right one, although I’ve increased the number of images to balance the labels, I have not yet been able to solve it. The underwater images are quite complex, as you may have noticed.
Another thing is that, I have grouped as jacks three sub species according to the list I made at the beginning in a single category (175 images), and with the tuna (90 images) I have done the same, this may be the explanation to what is happening to you, and as both can be silvered, the algorithm must have learned that these characteristics correspond to a jack. In the future I would like to do a better disaggregation in species labeling, but this is something I have not done yet.
Lately, I have been thinking that to improve the models and deal with lack of data and labeling issues, self-supervised learning could be a good alternative.
I hope this has answered your questions.
1 Like
This is a project I did applying collaborative filtering to a books dataset. The blog is mainly non-technical as I wanted it to be readable so no notebooks or code, but it has the results and in particular looks at latent factors in more detail. Naturally my blog is built using fast pages!
3 Likes
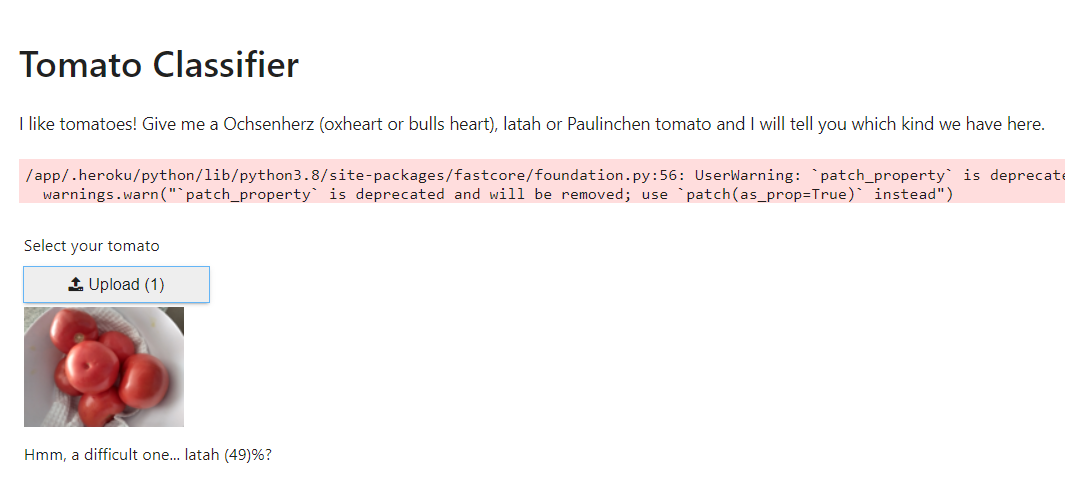
I woke up today and decided to open my language model to see what it is actually learning. My model was trained to generate molecules in the SMILES format.
Here’s some results
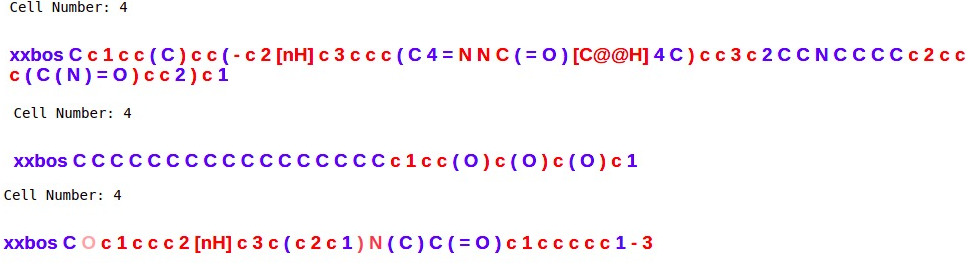
Cell number 4 means the fourth neuron of the last LSTM layer. As you can see, it fires when it sees a lower case “c”, which is an aromatic carbon.
7 Likes
fastai enables the implementation of CovidXrayNet. [Paper] [Code]
With only 30 epochs of training, CovidXrayNet achieves 95.82% accuracy on the COVIDx dataset in the three-class classification task (COVID-19, normal or pneumonia).
4 Likes
How to Deploy Fast.ai Models? (Voilà , Binder and Heroku)
Medium article:
code:
I hope this may help.
3 Likes
Car Type Classification
Classifies 4 types of cars.
- Convertible
- Pickup
- Sedan
- Station Wagon
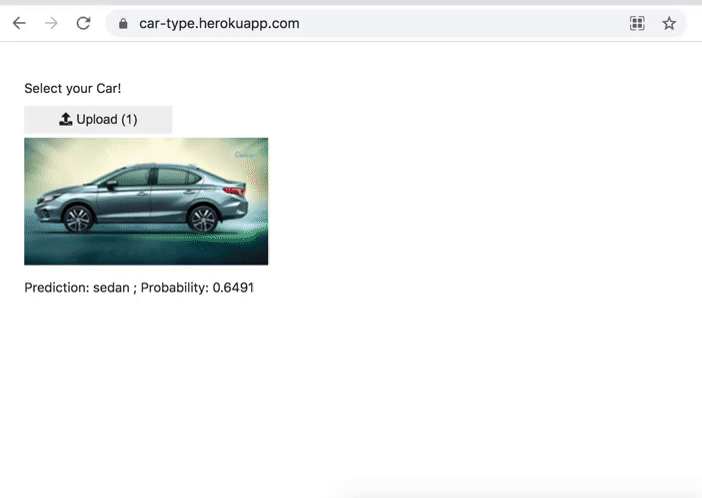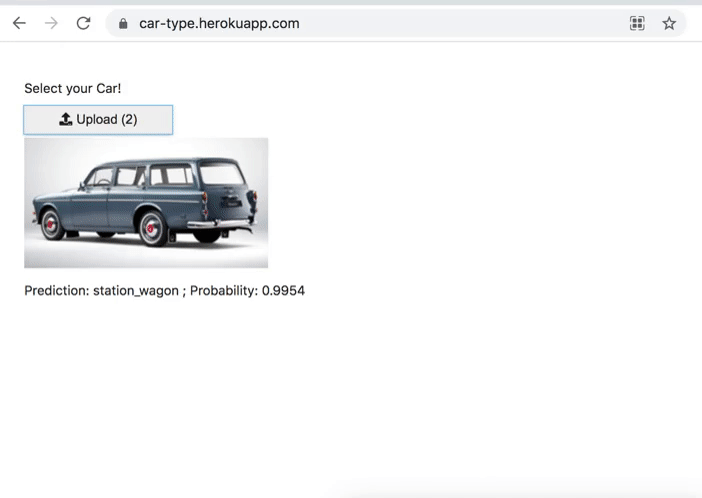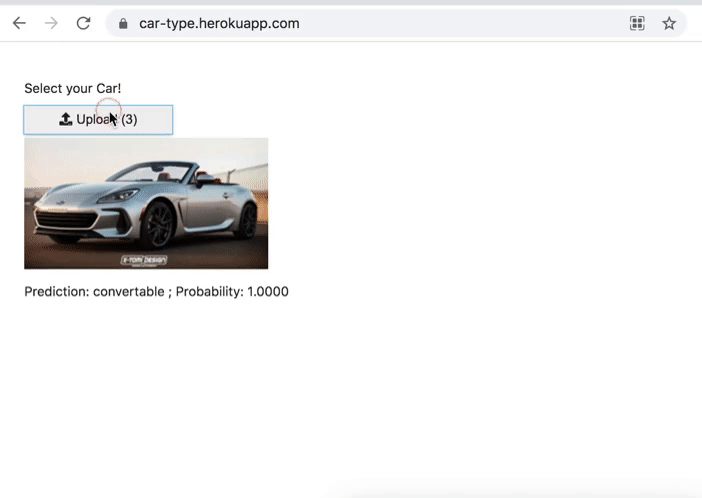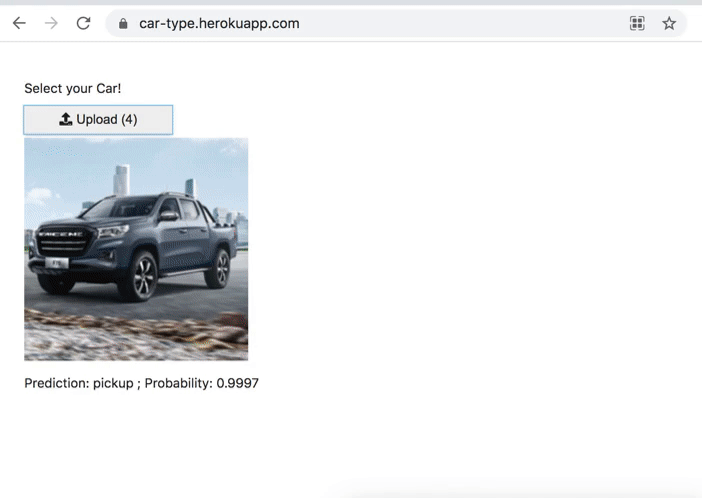
Medium:
1 Like
I use fast.ai to play with the Lung Sound dataset in Kaggle https://www.kaggle.com/vbookshelf/respiratory-sound-database .
In my kernel you can find how to use WeightDataLoader in fastai to oversampling sample and train_test_split to equally distribute classes between train/validation set.
https://www.kaggle.com/dienhoa/healthy-lung-classification-spectrogram-fast-ai
I think this topic is very interesting that anyone can have a cheap stethoscope and use it to monitor their heart or lung states. Then we can send it to the doctor if find something anomaly.
I will go further in this subject and try making an application to classify health’s state of lung/heart with stethoscope which I found it’s very helpful (Especially in the pandemic when we need to limit the contact as much as possible)
8 Likes
Once again, a new competition was announced on Kaggle, and I made a fastai starter notebook 
https://www.kaggle.com/tanlikesmath/seti-et-signal-detection-a-simple-cnn-starter
7 Likes
This is my work on the lecture 2 Bear classifier that uses Duck duck go. I know that this is nothing original, but I am a newbie to github and development coding and this was pretty challenging for me. Something like this would have helped me a lot. So I just wanted to share the whole thing just in case there are others too who are finding it hard and need something to cling to and boost their confidence.
4 Likes
I’ve just created a Web App for my project above Healthy Lung Classification Spectrogram Fast.ai | Kaggle .
https://scopai-ws.onrender.com/
This is for classifying lung’s health based on audio file recorded by digital stretroscope.
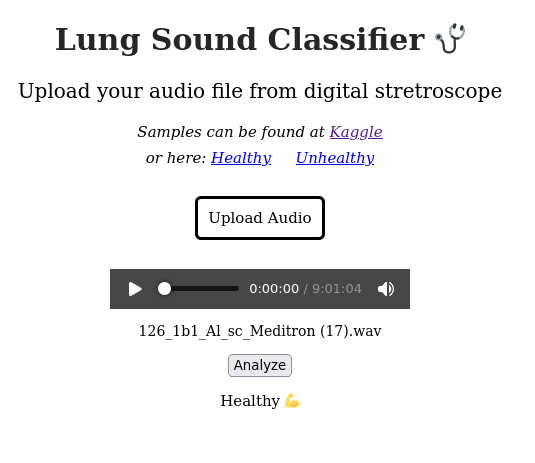
The app is deployed on Render.com .
Question: I’ve upgrade to Starter Plus on Render (15$/month - RAM 1Gb). However, the app is still slow (I have to wait about 40s to have the response). Anyone know which plan we should use on Render to make the app smoothly (based on the bear classifier for example) ? Thanks
[Update] Seems like it is a network problem. My file is about 2MB and it takes 36s to send the request. I’ve just tested my upload speed is about 7Mbps, so it might not be that slow, is it right ?
[Update] I changed the region to Frankfurt (I live in France) and the request take ~ 20s , it’s better but still not what I expected. However, it might because of my internet bandwidth ( Is 7Mbps upload speed can cause this problem ? ) . I’m very appreciate if someone can try to test the app speed. Thanks so much
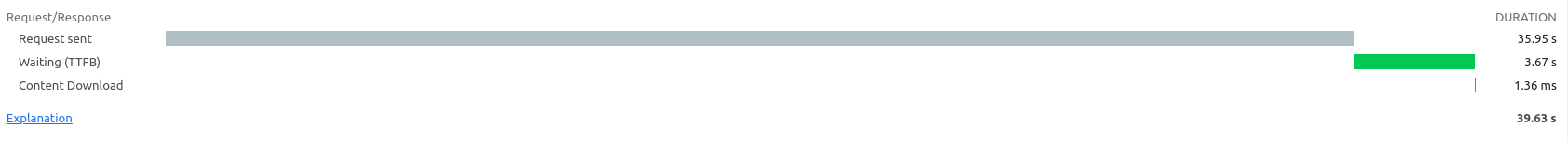
4 Likes
this is pretty cool! on my system, testing from Bangalore upload and analysis took less than 5 seconds. Would you be adding more features like identifying wheeze, types of breathing etc?
Cheers
AP
2 Likes
Thanks for your help. So the problems probably comes only from my Internet Speed.
Sure. I was thinking about working on detecting wheeze and crackles. But let me finish setting up a Blog for this project first. Thanks for your suggestions :D.
Hi all, is there any way to quantize and prune a fastai (with timm libaray) trained model, so that it can be deployed to mobile.
Currently, I am doing following:
effb3_model=learner_effb3.model.eval()
backend = "qnnpack"
effb3_model.qconfig = torch.quantization.get_default_qconfig(backend)
torch.backends.quantized.engine = backend
model_static_quantized = torch.quantization.prepare(effb3_model, inplace=False)
model_static_quantized = torch.quantization.convert(model_static_quantized, inplace=False)
print_size_of_model(model_static_quantized)
But I am facing following error, while calling the model for inference:
RuntimeError: Could not run 'aten::thnn_conv2d_forward' with arguments from the 'QuantizedCPU' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'aten::thnn_conv2d_forward' is only available for these backends: [CPU, CUDA, BackendSelect, Named, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, AutogradNestedTensor, UNKNOWN_TENSOR_TYPE_ID, AutogradPrivateUse1, AutogradPrivateUse2, AutogradPrivateUse3, Tracer, Autocast, Batched, VmapMode].
Thanks for any help…
Hi!
My chilean wildcats image classifier! I fine-tuned the model with about 100 pictures of each wildcat, and the model works decently discriminating between the 3 wildcat categories, but any normal cats fool the model really easy!
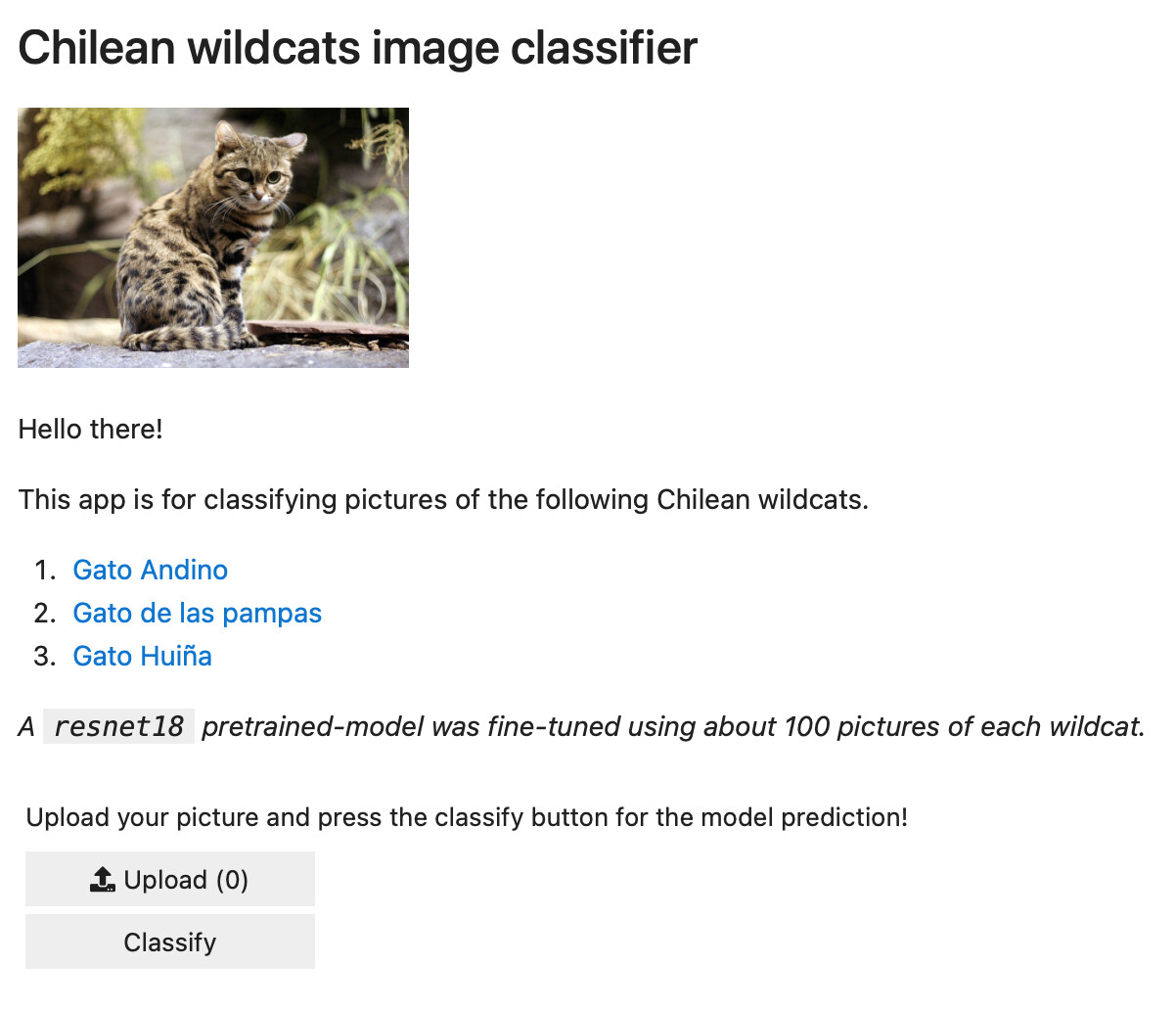
Link to the Github repo: GitHub - alcazar90/wildcats_app
2 Likes
Hello,
I have created an Image classifier to classify 250+ varieties of Indian food and hosted it on Algorithmia as an API. Please check out my medium article for details.
2 Likes
Wiki vs Blog to showcase a project and manage communications with team and a meetup group?
Please reply with your vote and why you think one will be better. Thanks!
Github repo: geo-ml/rainforest at main · JennEYoon/geo-ml · GitHub
- If I create a wiki, it will be at Github with the project repo.
Personal Blog: Blog-datasciY.com
- If I go with a personal blog, I will create a new page dedicated to this project.
I am in the early part of a geo-spatial machine learning project – Amazon Rainforest, based on a 2017 Kaggle Challenge from Planet Labs. I use fastai v2 and fastbook 2020 notebooks heavily.
I need to communicate with 2 others in the team and with a local meetup group. My written materials on various resources, notebooks I have developed, current and future ideas – are getting long and scattered. I also find myself repeating what I’ve said a lot when facing the whole meetup group. I already have a personal portfolio blog.
I would like to eventually make this project my best, special project – for getting a job in the field.
I am doing almost all the work on it now, and 2 others are giving me feedback, which I value very much. They may contribute more in the future, I don’t know.
So which is better? For showcasing my special project? For communicating with team and meetup group?
Thank you so much!
Jennifer Yoon “jenneyoon@gmail.com” for direct contact.
This is my 1st post, so not familiar with how messaging and posts works here yet.
1 Like