Hi ![]() vijish
vijish
Two words = Absolutely Fabulous. Great work a very polished notebook and repository. I ran it myself and the results are excellent.
Thank you very much for sharing.
Cheers mrfabulous1 

Hi ![]() vijish
vijish
Two words = Absolutely Fabulous. Great work a very polished notebook and repository. I ran it myself and the results are excellent.
Thank you very much for sharing.
Cheers mrfabulous1
Hi everyone,
I made an image classifier for airliners, fighter jets and attack helicopters. I cannot find any sensible reason why I chose this specific area 
With that said, the results are very good. The source is on GitHub and the model is deployed on Heroku, go and test it folks 
I’ve rambled through the topic and there are pretty amazing applications, congratulations everyone!
Long live fastai!
@VishnuSubramanian, @ilovescience thank you both for replying. I understand and will have a closer look at how that was done in the notebook shared by @ilovescience.
Hey, this is not a deep learning project but nevertheless something I’d like to share. My first blog post, Getting started with fast.ai
I answer some questions a beginner might have and offer advice I wish I had when I started the course.
I’d be happy if you guys check it out and let me know what you think of it or how to improve it. And if you like it, share it with somebody who’s interested in getting started with deep learning!
Hi johannesstutz I hope your are having a wonderful day!
I found your blog informative, interesting and enjoyable. I think it would make a great read for any person starting out in AI/ML
AI should not replace humans, it should support them!
Data Ethics
I am really happy you mentioned the above two items, as these to me are probably, two of the most important issues facing humanity in relation to AI.
Great Work
Cheers mrfabuous1 ![]()
![]()
That’s so nice to hear, thank you @mrfabulous1 !
And yes, being aware of the ethical implications of AI is really important in my opinion, and I’m glad that Rachel and Jeremy teach us to ask the right questions.
Hey guys,
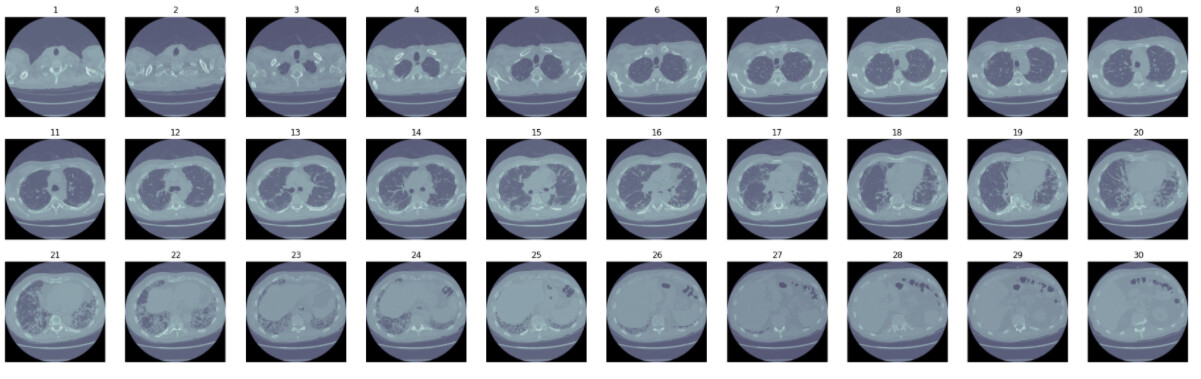
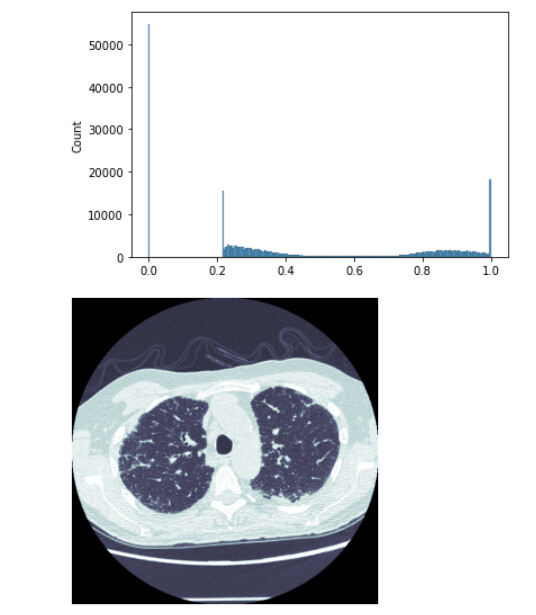
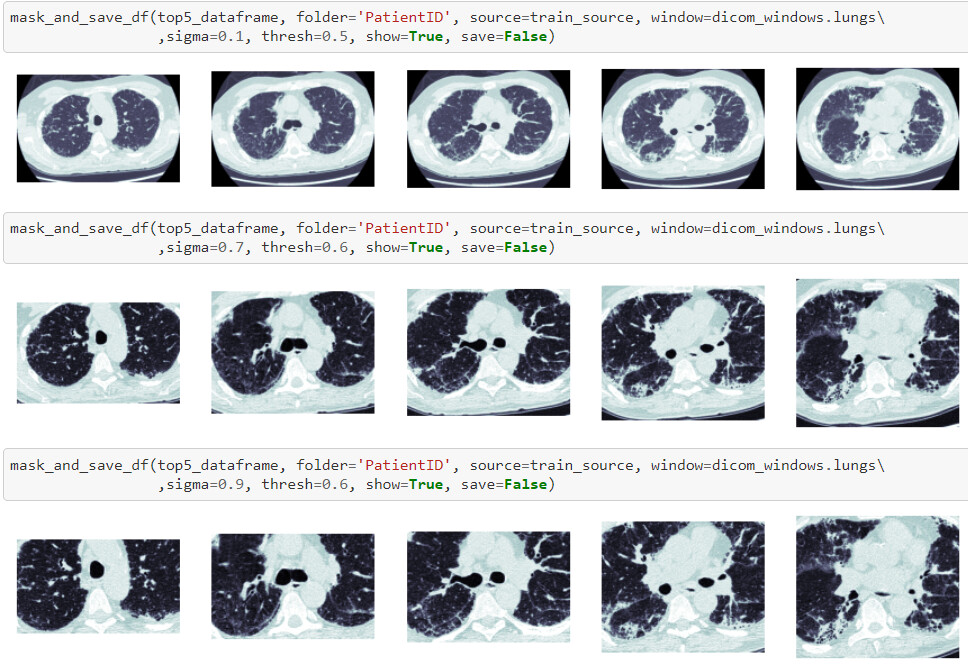
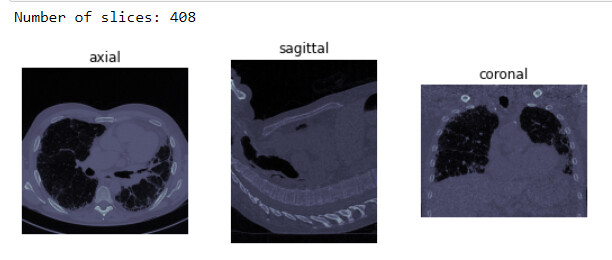
Excited to share fmi, a project that is built on top of fastai’s medical imaging module. The first tutorial is out and it currently goes through the first 2 out of 5 sections (exploration and preprocessing). Some examples:
Easily view image slices in sequence
View images in the axial, sagittal and coronal planes
View image pixel histograms
Mask and save images
Convert .dcm to .jpg and where each channel represents a different window width and length
See how dicom splitter works checking to see if the same patient exists in the train and valid sets
The goals of this tutorial are:
Explain some of the features of the fmi library
Medical imaging datasets are often large(in the tutorial example there are over 32600 images). What can we do to reduce the size of the dataset for initial prototyping
Explain how to remove areas of images that have no relevance to the training process
Save .dcm images into .jpg format where each channel represents a different window width and level
With medical datasets it is important to ensure that the same patient is not represented in the training and validation datasets. Explain how dicom_splitter works in ensuring the same patient is not represented in both sets
Show example DataBlock’s
Hope you enjoy it!
This looks nice but it does not run under V2. Looks like it was made with V1.
Hey guys,
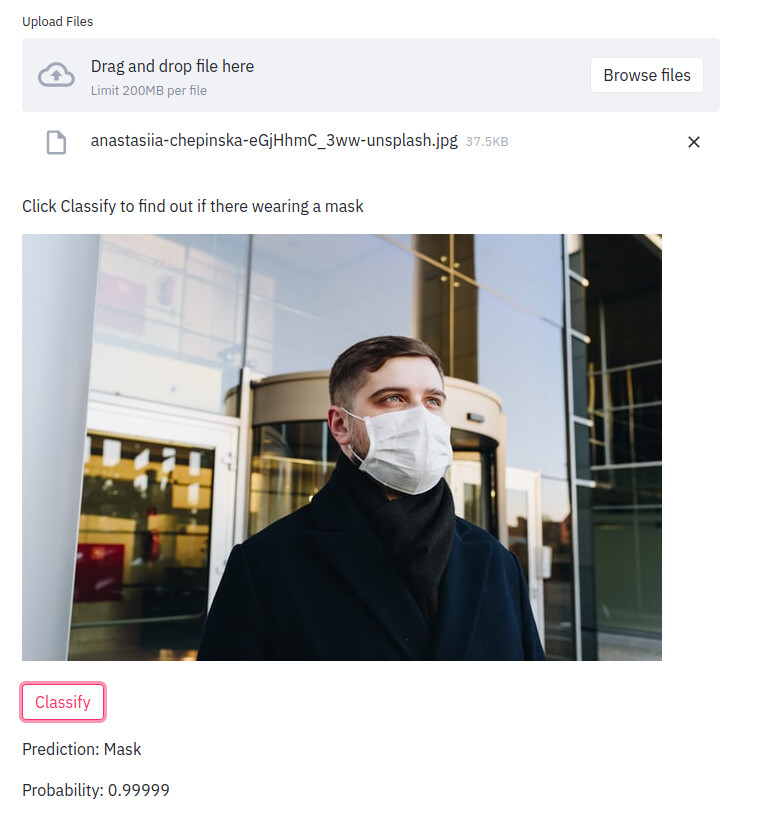
I made an image classifier for people wearing COVID masks. It works pretty well but only supports still images. Jeremy recommended using Binder to host web apps, but I found that a little slow.
I added it to a simple Streamlit app here and the GitHub is here, I also wrote a Medium article here.
Thanks to all at FastAI for all the hard work. If I could be doing anything better let me know ASAP.
Nice, the deployment on Streamlit looks really good and runs pretty quickly. Definitely keeping this in the back of my head.
Check your medium article, there’s something wrong with the included code
Did you add more pictures of bearded faces with the new label, or did you reorganize and re-label the existing dataset? It would be really interesting if you improved performance just by adding a new label, I think. (In production, you could then treat no-mask and beard as the same label)
And thank you for mentioning the problems with datasets that are not diverse
First of all, thank you for heads up on Medium! It seems to be fixed now.
I created a new label “beards”, with the only change being search query. The performance is very much limited by the accuracy of the search results, so spending a bit of time on the data cleaning section is essential. In Streamlit, I treat the beards and no mask the same as you said:
if str(pred) in ('no_mask', 'beard'):
pred = 'No mask'
else:
pred = 'Mask'
If anyone is interested in optimal transport as a distance metric, I’ve been doing some work on a few OT algorithms
Hi jackharding hope all is well!
Great post ,
After solving the beard issue, I realised the same problem could crop up with different ethnicities as most of the images search results were white men. I did not initially consider this when starting this and something I should include in future computer vision projects. I’d recommend FastAI’s lesson on data ethics for an expansion on what I just mentioned.
I am impressed with your use of the ethics chapter and you observed possible natural biases in the model.
Yours is the first post in this thread that has explicitly mentioned they considered ethics.
An example we can all follow.
It is likely the his failure for some facial recognition software to made ethically or used in unethical ways has lead to decisions such as this Massachusetts Lawmakers Vote To Pass a Statewide Police Ban On Facial Recognition
Cheers mrfabulous1 ![]()
![]()
![]()
My second blog post is online!
I just finished Chapter 5 from the book and decided to use what I learned about Image Classification on a problem from my research field. Can we actually train models to predict bioactivity from nothing but a molecule image?
Thanks for sharing your blog post. I think it’s really interesting. Keep up with your great work!
Once again, a new competition was announced on Kaggle, and I made a fastai starter notebook 
https://www.kaggle.com/tanlikesmath/ranzcr-clip-a-simple-eda-and-fastai-starter
I wanted to take the lesson on deployment a step further and ended up creating a fully featured web app (with user accounts etc) for yoga pose recognition and evaluation. It’s still work in progress (the model was trained less than 10 minutes, no fine tuning) but feel free to check it out at https://yogapose.app.
For those of you interested in time series/ sequential data, I’ve just added a new tutorial notebook on how to apply TSBERT a self-supervised, BERT-like approach for time series. I’ve tested it on a few datasets, and the results are pretty good.
You can get more details here:
Thank you for the post and the great notebook for the competition.
I was wondering about the different metrics for evaluating models and why one might be chosen over others. In particular, in this competition, when many of the categories are mutually exclusive. For example, for the ETT categories – an xray could be reported as ETT – Abnormal OR ETT – Borderline OR ETT – Normal OR none (if no ETT), but not more than one of these. It confused me that they seem to treat each category as independent labels to assess overall how good the model is. Hoping someone with more datascience or statistical background can provide an explanation.
So, using fastai and Flutter, I’ve now got an Android app on the Google Play store!
The app is called “yogapose”. It identifies and gives a score for your yoga posture. Feel free to try it out here: https://play.google.com/store/apps/details?id=app.yogapose
Suggestions, ideas are most welcome.