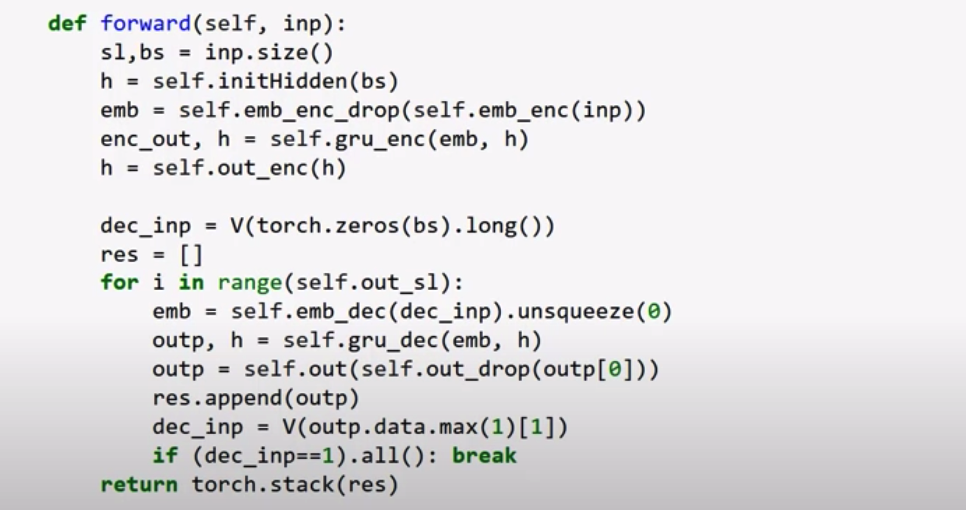
From the video about neural translation (attached screenshot below), in the forward pass of the decoder, why is the output decoder hidden state reinjected after each iteration instead of only using encoder hidden state? And it would even harm the learning, because then the decoder wouldn’t be decoding the encoder anymore but decoding its own output?
From what I understand. the loop is being using because nn.rnn cannot use the output at cell N for input at N+1. Ideally, we’d do the above loop in one forward pass, where enc hidden state is used and then predictions are chained to subsequent decoder unit’s input. Is this right?
If it is, then we would want to keep the same encoder hidden state in each iteration, and then the loss be calculated only for the tensors last iteration. In the last iteration, we would’ve gone through the decoder, chaining predictions into inputs for all units, with the loss to be calculated only on this timestep
You only want to give the final hidden state of the encoder as an input to the first step of the decoder. This hidden state reflects the encoding of your input sequence. But then, when decoding, you want to allow the decoder to modify the hidden state at each step. In this sense, the knowledge from the encoder can still reflected in the hidden state, but it can be modified to improve the decoding process.
The loss is calculated after the whole batch is processed, but it is calculated for the entire sequence. The error signal is then backpropagated through all time steps to change your weights in a way that would improve the model’s prediction at each time step, not just the last one.