Is it just me or is the sentiment analysis model using the IMDB dataset in Lesson 1 really bad since its accuracy is very poor when I run some test on it although the training code cell output shows an accuracy of 0.92. Or am I doing something wrong. Please help.
Hi Rajarshi1 hope you are having a beautiful day!
-
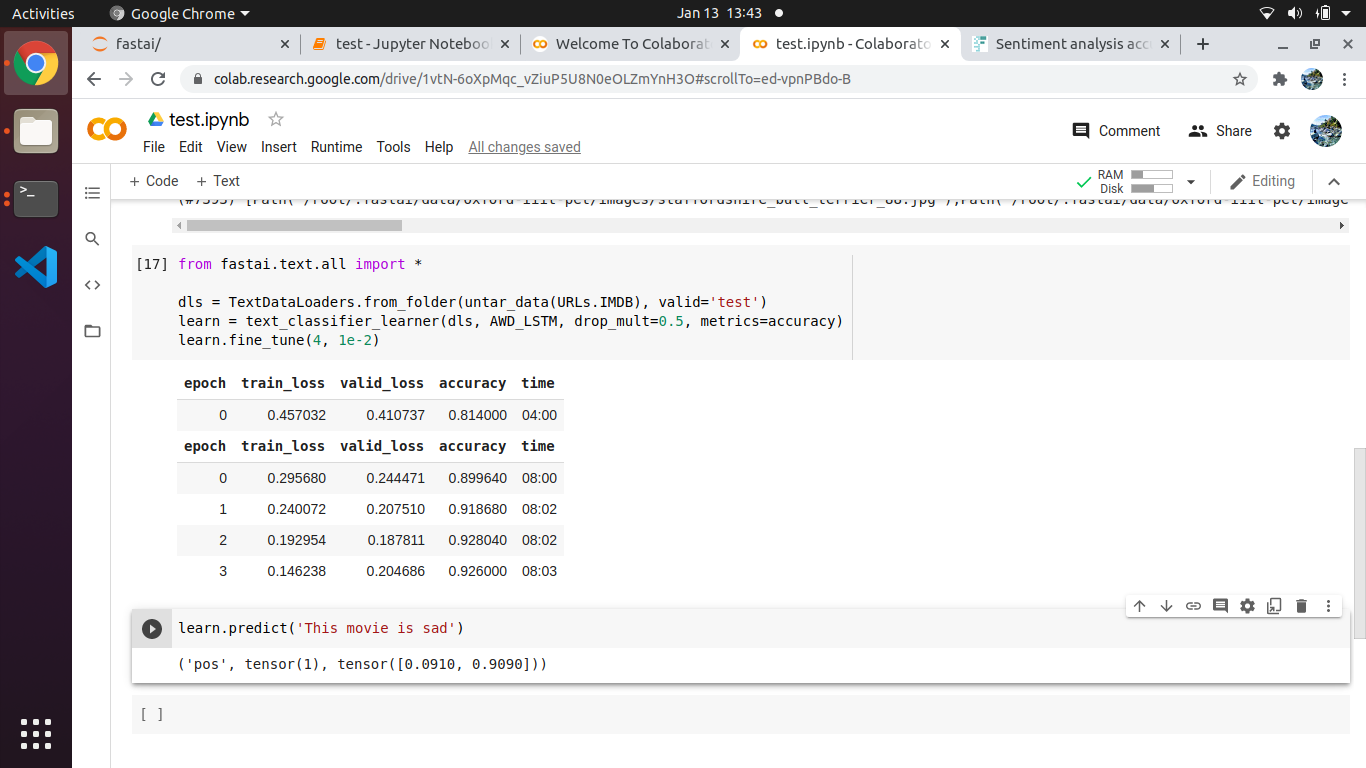
Running the exact same code as shown in the diagram with one difference - training is done with the following parameter settings (2, 1e2).
-
Seems to produce better results.
epoch train_loss valid_loss accuracy time
0 0.456642 0.391752 0.823480 03:44
epoch train_loss valid_loss accuracy time
0 0.296570 0.278636 0.886960 07:36
1 0.220235 0.198710 0.922680 07:36
3
('neg', tensor(0), tensor([0.7191, 0.2809]))
- Also if you try these two statements you may notice order of words makes a difference.
movie_rec = "I loved and hated that movie"
prediction = learn.predict(movie_rec)
movie_rec = "I hated and loved that movie"
prediction = learn.predict(movie_rec)
Maybe training slightly less will help.
Cheers mrfabulous! 
1 Like
Hey hi! Thanks for that! Question: How do I train it “slightly less”? hehe newb here please help
Hey @mrfabulous1 I ran the test with (2, 1e2) parameters and this was the result:
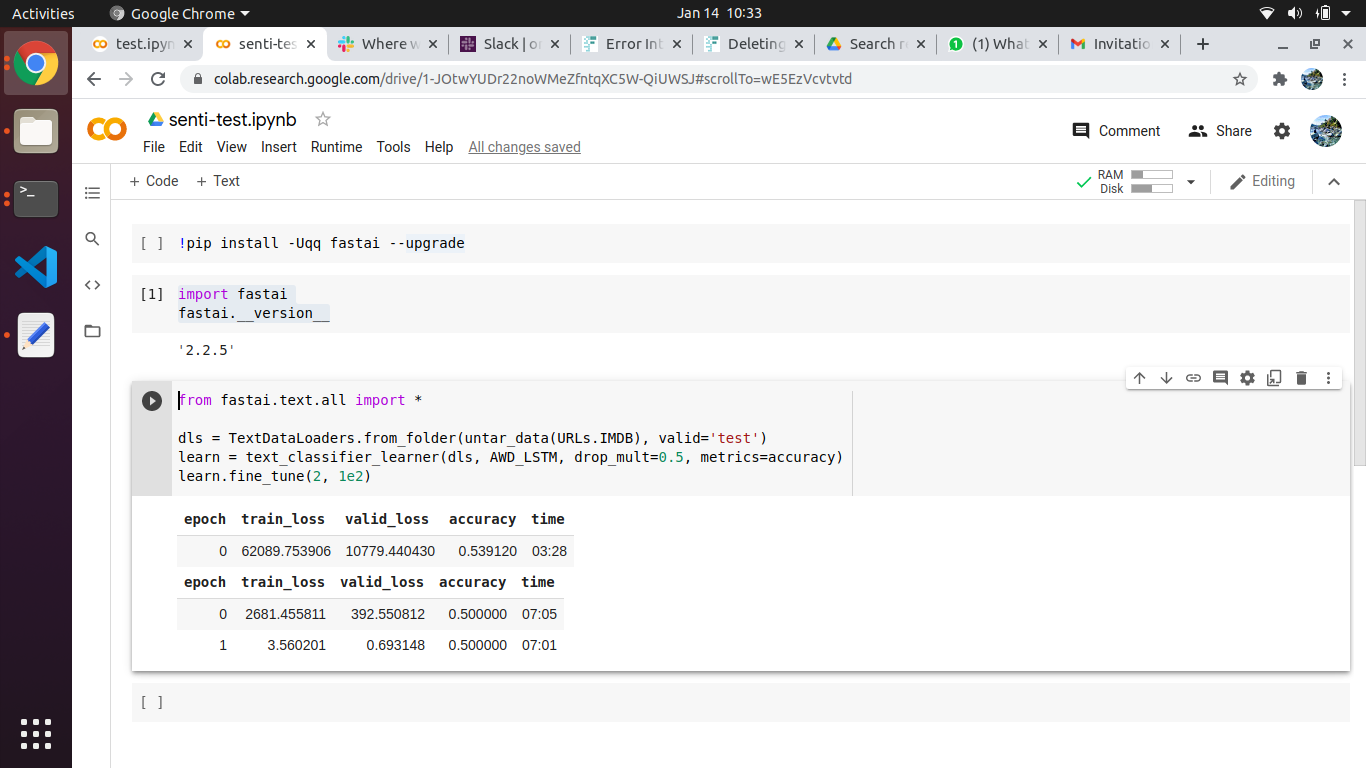
accuracy - 0.50
lol
Hi Rajarshi1 hope all is well!
Not sure what the problem is, your code looks okay and is running the same version as mine.
Normally I would suggest running
learn.summary() and dls.summary() but they don’t seem to be working on this tabular dataset at present. 
Try running learn.lr.find()
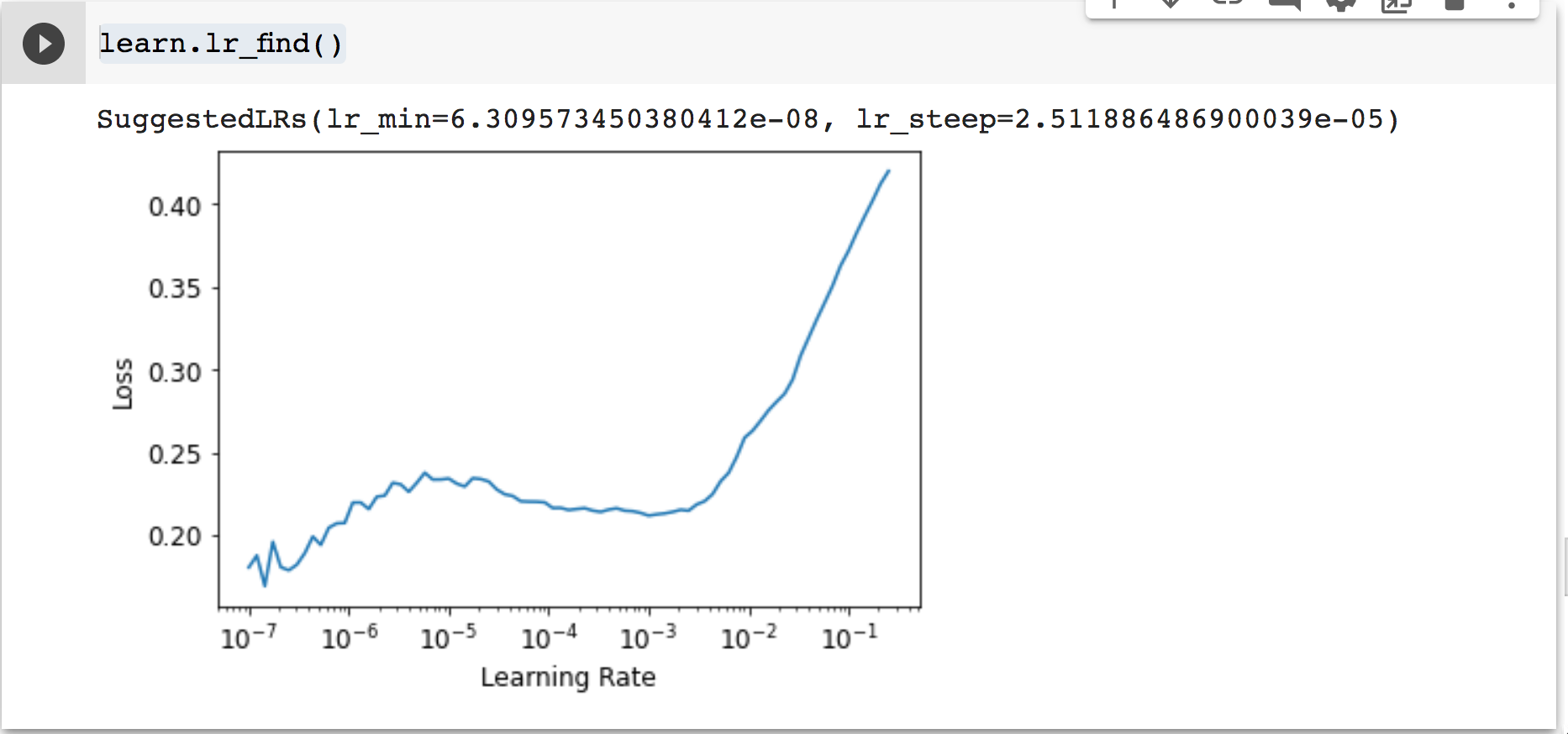
This is what mine looked like this morning.
Maybe you could experiment with some different learning rates?
Cheers mrfabulous1