@jeremy I’ve been attempting to use the pre-trained LM from lesson 10 to create sentence vectors. I’d like to use the vectors to create a semantic search system.
My first attempt at using pooled hidden states as vectors ( described here ) showed that semantically different sentences weren’t appreciably different from semantically similar ones. Further attempts to build a classifier from the LM to predict entailment yielded similar results. The classifier is a Siamese Network available here
Questions:
Should the pooled hidden states of a LM produce vectors suitable for determining sentence similarity? In other words, would you expect 2 semantically similar sentence to have a greater cosine similarity than 2 unrelated sentences?
I’m not sure how to proceed. Does this look like a reasonable approach? What do you do when you get stuck on a problem like this?
ULMFit is all about fine-tuning. I wouldn’t expect it to work without that step. I would expect it to work well for semantic similarity if you fine tune a siamese network on a ULMFit encoder.
Update on my progress:
I made 2 changes that have boosted my performance from 40% to 50%.
The first was to sort my sentences by length.
The other was that I switched to the MultiBatchRNN encoder.
50% is still a very poor result, so I’m going to dig in further to the InferSent code to what might be different.
The other thing I did was to validate my loader and model code with the original IMDB task.
I was able to get good results, but not as good.
Update: I’ve gotten 61% accuracy now. Better but not great. Infersent gets an accuracy of 84.5% on SNLI.
Update: I changed my vector concatenation to the way that InferSent does it. So my forward pass now looks like this:
def forward(self, in1, in2):
u = self.encode(in1)
v = self.encode(in2)
features = torch.cat((u, v, torch.abs(u-v), u*v), 1)
out = self.linear(features)
return out
When I’m running your ULMFit_classify after running other two notebooks it’s giving me an error. Says “ValueError: optimizing a parameter that doesn’t require gradients”. I have been stuck here for the past few hours!!
Hello Brian, I got it to work but I’m not able to train it. When I’m running the fit function with multiple epochs I’m running out of GPU memory. I’m using Google Compute Engine with tesla 11gb memory. Which GPU did you use? Also if its possible can you please upload your pre-trained model? That would be a really good help for me. I’ve attached a picture where I run out of memory. After running this cell, it gives me CUDA memory error. I’ve also tried reducing the batch size.
Hey Brian, I only found one file for the model which is snli_language_model.pt. I’m looking for the siamese_model0.81.pt file that you trained. When I try to load the language model you gave me as siamese_model it gives me an error. I believe there suppose to be another file for siamese model.
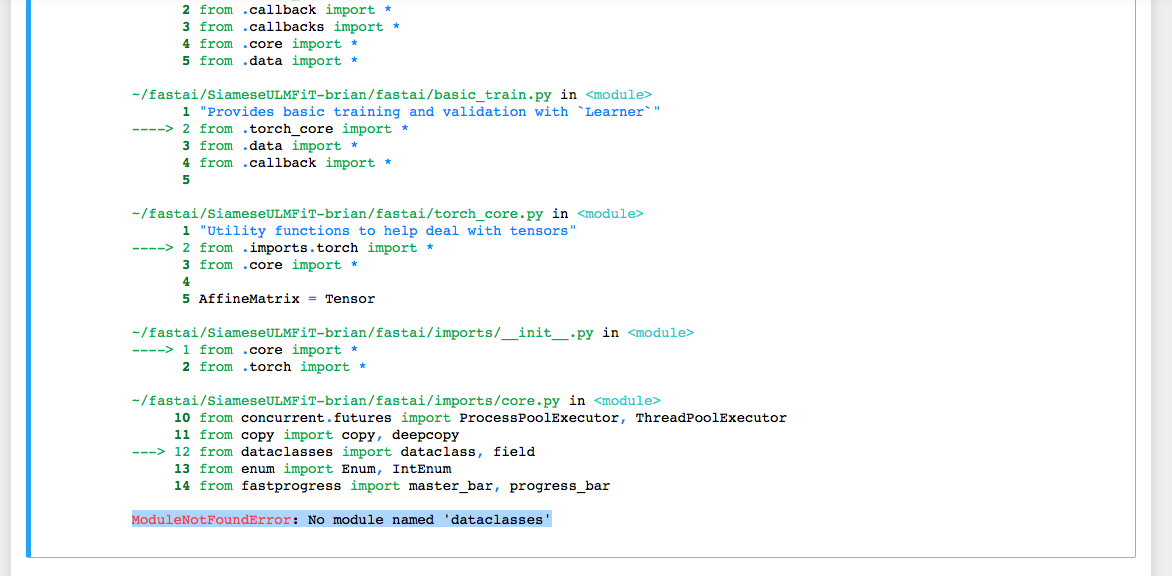
Hey Brian, so i updated to the version or torch you’re using by $ pip install ‘torch==0.4.1’ and now i’m getting this error. I’m using the instruction from this link to install fastai Fastai v0.7 install issues thread . After creating a virtual environment, i’m installing torch 0.4.1 as the default fastai installation is 0.31. But after running ULMFIT_classify notebook i’m getting this error.
btw, this is the first cell in the notebook where all the imports are happening. Which version of python are you using. I’m using 3.6.6 and I believe that might be the issue. When I made a virtual environment with python 3.7 I’m getting another error. Please help!!!