Hi, guys:
I am happy to announce that I have released SemTorch.
This library allows you to train 5 different Sementation Models: UNet, DeepLabV3+, HRNet, Mask-RCNN and U²-Net in the same way.
For example:
# SemTorch
from semtorch import get_segmentation_learner
learn = get_segmentation_learner(dls=dls, number_classes=2, segmentation_type="Semantic Segmentation",
architecture_name="deeplabv3+", backbone_name="resnet50",
metrics=[tumour, Dice(), JaccardCoeff()],wd=1e-2,
splitter=segmentron_splitter).to_fp16()
This library was used in my other project: Deep-Tumour-Spheroid. In this project I trained segmentation models for segmenting brain tumours.
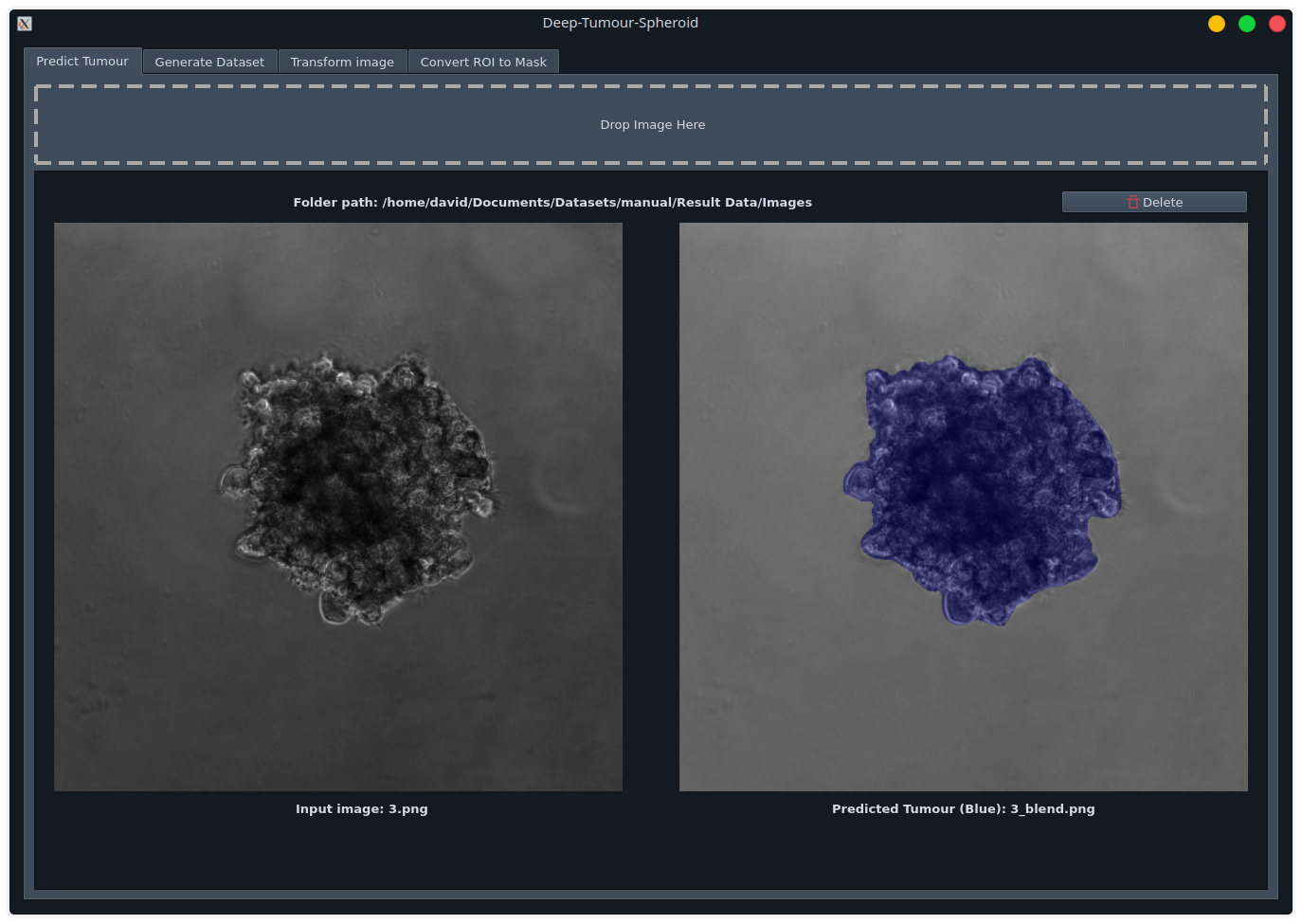
The notebooks can be found here. They are an example of how easily is to train a model with this library. You can use SemTorch with your own datasets!
In addition, if you want to know more about this project you can go to
Deeper look in all the parameters of Semtorch
All this library is focused in this function that will get new models and options over time.
def get_segmentation_learner(dls, number_classes, segmentation_type, architecture_name, backbone_name,
loss_func=None, opt_func=Adam, lr=defaults.lr, splitter=trainable_params,
cbs=None, pretrained=True, normalize=True, image_size=None, metrics=None,
path=None, model_dir='models', wd=None, wd_bn_bias=False, train_bn=True,
moms=(0.95,0.85,0.95)):
This function return a learner for the provided architecture and backbone
Parameters:
- dls (DataLoader): the dataloader to use with the learner
- number_classes (int): the number of clases in the project. It should be >=2
- segmentation_type (str): just
Semantic Segmentationaccepted for now - architecture_name (str): name of the architecture. The following ones are supported:
unet,deeplabv3+,hrnet,maskrcnnandu2^net - backbone_name (str): name of the backbone
- loss_func (): loss function.
- opt_func (): opt function.
- lr (): learning rates
- splitter (): splitter function for freazing the learner
- cbs (List[cb]): list of callbacks
- pretrained (bool): it defines if a trained backbone is needed
- normalize (bool): if normalization is applied
- image_size (int): REQUIRED for MaskRCNN. It indicates the desired size of the image.
- metrics (List[metric]): list of metrics
- path (): path parameter
- model_dir (str): the path in which save models
- wd (float): wieght decay
- wd_bn_bias (bool):
- train_bn (bool):
- moms (Tuple(float)): tuple of different momentuns
Returns:
- learner: value containing the learner object
Supported configs
| Architecture | supported config | backbones |
|---|---|---|
| unet | Semantic Segmentation,binary Semantic Segmentation,multiple |
resnet18, resnet34, resnet50, resnet101, resnet152, xresnet18, xresnet34, xresnet50, xresnet101, xresnet152, squeezenet1_0, squeezenet1_1, densenet121, densenet169, densenet201, densenet161, vgg11_bn, vgg13_bn, vgg16_bn, vgg19_bn, alexnet |
| deeplabv3+ | Semantic Segmentation,binary Semantic Segmentation,multiple |
resnet18, resnet34, resnet50, resnet101, resnet152, resnet50c, resnet101c, resnet152c, xception65, mobilenet_v2 |
| hrnet | Semantic Segmentation,binary Semantic Segmentation,multiple |
hrnet_w18_small_model_v1, hrnet_w18_small_model_v2, hrnet_w18, hrnet_w30, hrnet_w32, hrnet_w48 |
| maskrcnn | Semantic Segmentation,binary |
resnet50 |
| u2^net | Semantic Segmentation,binary |
small, normal |
