If you have access to lots of unlabeled data, but a relatively small amount of labeled data, Semi-Supervised Learning (SSL) might be really useful.
In the last few months, several new SSL techniques have been designed substantially raising the state-of-the-art bar.
Some of these techniques are:
- UDA (Apr 2019): Unsupervised data augmentation. arXiv preprint arXiv:1904.12848 (original TensorFlow code)
- MixMatch (May 2019). Mixmatch: A holistic approach to semi-supervised learning. arXiv preprint arXiv:1905.02249 (original TensorFlow code)
- S ^\mathbf {4} L (May 2019). S ^\mathbf {4} L: Self-Supervised Semi-Supervised Learning. arXiv preprint arXiv:1905.03670
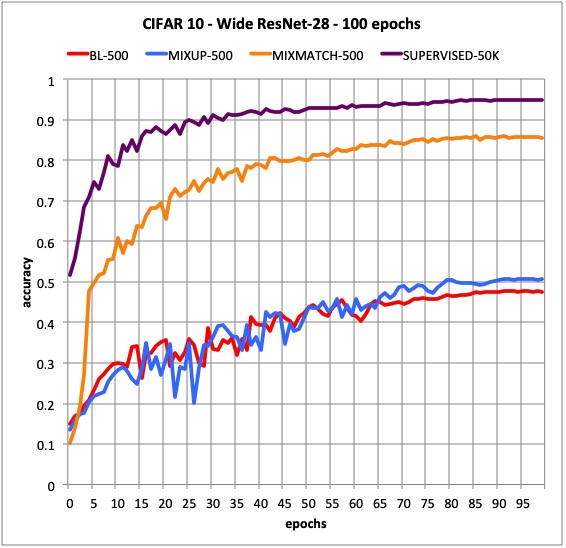
Just to give you an idea of how powerful these techniques are, here’s the result of some experiments I’ve run:
- BL-500 uses supervised learning with 1% of the full CIFAR10 dataset (500 /50k).
- Mixup-500 uses the same 1% + Mixup
- Supervised 50k uses supervised learning with the entire CIFAR10 dataset
- MixMatch-500 uses 500 labeled samples + 49.5 unlabeled.
I think it’s impressive to get this type of results with just 1% of the labeled examples!
You may also find some Pytorch implementations of these techniques here.
I have added 2 new notebooks to my fastai_extensions repo called04a_ MixMatch_extended and 04b_MixMatch showing you how you can now use this technique with fastai. Both notebooks contain the same code, but the first one has some more details on how it can be used.
Most of the code is based on a fantastic repo and Medium blog post created by @noachr. I’d really like to publically thank him for his contribution  . He deserves all the credit for this work. He shared his code here. It’s one of the best notebooks that I’ve seen.
. He deserves all the credit for this work. He shared his code here. It’s one of the best notebooks that I’ve seen.
I have just simplified the code, made it a bit faster and easier to use. You’ll just need to add this to your code:
learn.mixmatch(ulist)
with the list of unsupervised samples. That’s it! I hope you’ll find it useful as I have!