I’ve got an application where I need to accurately classify a set of multiple items in a container, and I’m looking for some advice on model architecture for how to solve this problem. Since the application has some confidentiality, I’ll propose an analogous problem that shares notable features with my application: Sorting collector coins by which design they’re minted with.
Let’s imagine I have a collector’s coins business and I need to fulfill orders of specific state/year US quarters to the collectors. When I fill the orders, I want to run the quarters through an automated check that I’ve got the right coin.
Features of the problem:
⁃ I’ve already got the quarters in cups, and they should all be identical quarters in the cup
⁃ I’ve got a fixed webcam that I can put the cups under that’s taking the photos
⁃ Each cup will have multiple quarters, not necessarily facing the same direction (face up or down)
⁃ The check will output either a confirmation that it’s the right kind of coins, or it will prompt for a human to check.
⁃ I want to automate checks for as many of the quarters as possible, but since some of these coins are quite valuable, I’d rather optimize for precision at the cost of recall.
⁃ There are hundreds of types of quarter, so only being able to precisely classify a subset of them is okay
⁃ If the model lends itself to active learning as I check the quarters or capture more photos of rarer coins that would be big plus
The previous way I’ve approached this problem is as follows:
⁃ Train an object detection model that’s capable of drawing a good bounding box around each quarter
⁃ Train a resnet classifier to classify the individual coins into classes
⁃ Run inference:
⁃ Use the object detector to draw bounding boxes on the image with multiple quarters
⁃ Crop out each quarter
⁃ Run that cropped image through the classifier
⁃ Combine together the results of each resnet classification
Full image -> segmentation -> crops -> classifier -> vote aggregation

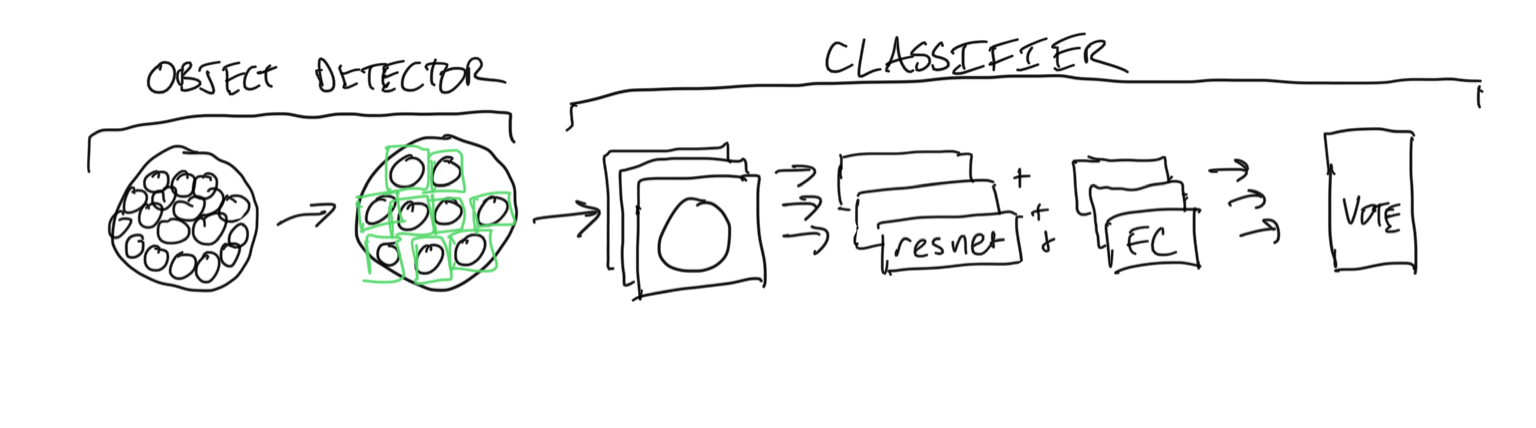
I’ve tried aggregating the resnet results both by using each result’s single label as a vote, and also by summing the output of the final softmax and picking the highest value that way. Right now this technique performs pretty well on classes that are not as similar to one another (i.e. different sizes or colors of coin) however, on coins that are very similar save for some fine detail, the model is sometimes a bit of a coin toss between them. It also seems to suffer a bit as the number of classes increases, although the added classes have fewer training images as well which is a confounding factor.
One weakness with this approach is that this approach forces each neural-net classification to be done in a vacuum, whereas the comparable human task is more likely to involve looking around at a couple of coins and making an evaluation based on the aggregate. To improve the performance, I’ve been thinking that it would help to use a model architecture that allows for the model to learn about the whole ensemble of coins in the image. Since they’re all the same in a coin cup, it seems like using the group should provide more information to the model than just each tiny classification task. Some model architecture ideas that I’ve thought of are below:
⁃ Super basic version: make a resnet-based classifier that runs on the full images, not the crops
⁃ Use a deep metric learning approach by training a backbone with contrastive, triplet, or other multi-pair wise loss function and use Euclidean distance or cosine similarity to compare the mean of a group of cropped coin embeddings against known embeddings. I know embedding similarity approaches like this can perform well on fine-grained classification tasks, such as similar-looking coins.
The model idea I’m most interested in fleshing out, however, is as follows:
⁃ Make a model that takes in multiple crops from the full-cup image, runs each of them through the backbone layers of a resnet and obtains an activation for each crop, then combines them into a single activation of fixed length (using max pooling?) which would then pass through two fully-connected layers at the end and be classified.


This model idea based on the default cnn_learner in fastai, with a resnet backbone feeding into two fully connected layers that perform the final classification. The goal is to allow the FC layers at the end to look at some representation of “all of the coins in an image” instead of only looking at individual images. Hopefully this will allow the training process to internalize some idea of which kinds of cropped images are more informative than others, so that the pooled activations are more representative of each class.
I have a few questions about this model:
⁃ Is it possible to have a module that will run sets of resnet backbones on the variable number of cropped images that this model will produce between images?
⁃ Does this plan pass the smell test? Will it likely achieve what I’m describing?
⁃ In making the classifications, since the fronts of coins will look relatively similar to one another and the backs much more identifying, is it likely better to separate fronts and backs of coins into separate classes?
In addition, I would appreciate any advice on other architectures/pipelines that might be better suited to this task. In keeping with the coin identification question, the ability to perform with pretty high precision on fine-grained classification is key, especially across large numbers of classes (relatively low recall is okay here, it can be kicked back to a human for verification).
Thank you!