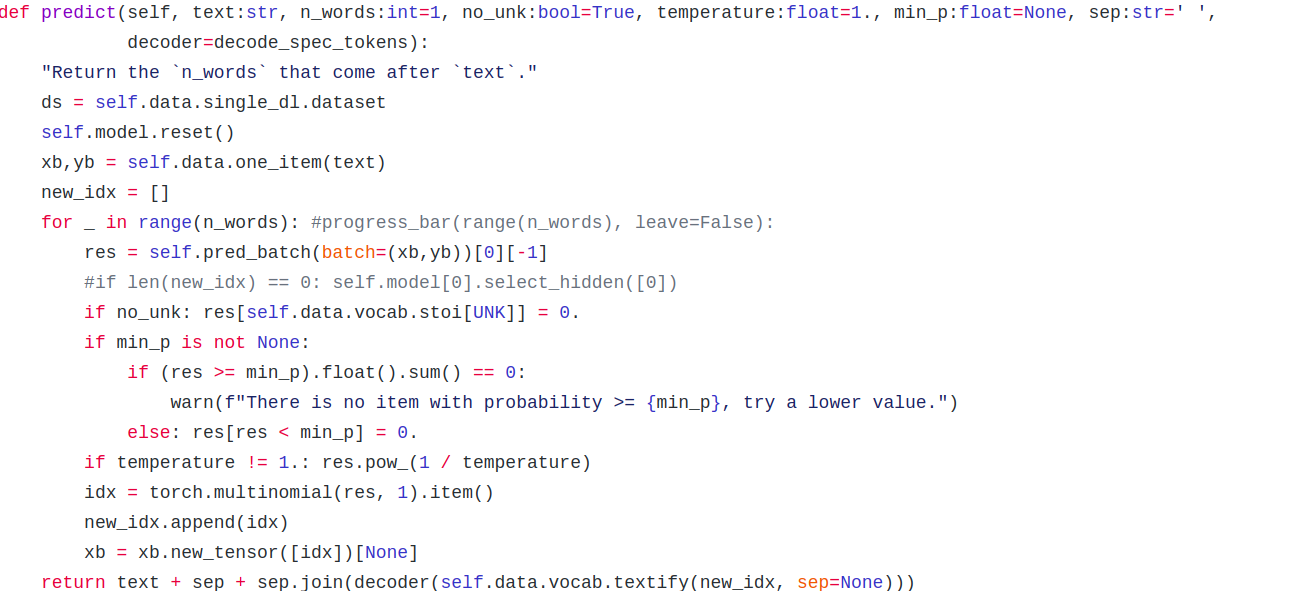
Lately, I have been working on implementing ULMFiT Pipeline using AWD_LSTM. In the Language Modeling part, I want to see the possible word predictions for the next word.
The students opened their ___________ [books, bags, shoes etc., all of these are possible predictions but is there any existing way to get them]
Currently, all we get is the next word after a bit of randomness as below [Atleast, that’s what I understood].
You can see that you can call pred_batch() on the learner (I think) and then get an output vector of the probabilities in your vocab. From there you can take the top N that you would like to look at and consider the differences in probabilities between the following words.
Do you want to do this for single examples or in some batched way for a bunch of cases?
Is this what you are looking for?
from fastai.text import *
path = untar_data(URLs.IMDB_SAMPLE)
data_lm = TextLMDataBunch.from_csv(path, 'texts.csv')
learn = language_model_learner(data_lm, AWD_LSTM, drop_mult=0.5)
learn.predict("this is a")
Out:
'this is a "'
Your case:
xb, yb = learn.data.one_item("this is a")
lrn_out = learn.pred_batch(batch=(xb,yb))
torch.topk(lrn_out[0][-1],5)
You could inspect the vector of the last word and do whatever you might like to understand the outputs.
You map the indices back to words as in teh example you posted above with learn.data.vocab.textify()